
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 백준 1034 램프 파이썬
- 백준 2352 반도체 설계 파이썬
- 램프 파이썬
- 백준 1613 역사
- SQL SERVER MIGRATION
- SQL SERVER 장비교체
- 백준 11054.가장 긴 바이토닉 부분 수열
- 가장 긴 팰린드롬 파이썬
- 역사 파이썬
- 프로그래머스 등굣길
- 백준 1516 게임 개발
- 트리의 지름 파이썬
- 백준 1043 거짓말 파이썬
- 베스트앨범 파이썬
- 반도체 설계 파이썬
- SWEA
- 등굣길 파이썬
- 다중 컬럼 NOT IN
- 순위 파이썬
- 가장 긴 바이토닉 부분 수열 파이썬
- 프로그래머스 베스트앨범
- 프로그래머스 여행경로
- 백준 1167 트리의 지름 파이썬
- 백준 1238 파티 파이썬
- 다리 만들기 파이썬
- 프로그래머스 가장 긴 팰린드롬
- 백준 2146 다리 만들기
- 게임 개발 파이썬
- 프로그래머스 순위
- 프로그래머스 순위 파이썬
- Today
- Total
공부, 기록
[AWS] Aurora 공부 2 (Aurora의 기능들) 본문
2024.07.04 - [공부/DATABASE] - [AWS] Aurora 공부 1 (아키텍처와 특징)
[AWS] Aurora 공부 1 (아키텍처와 특징)
1. 내부 아키텍처Aurora 는 클러스터 볼륨이라는 특수한 스토리지 구조를 가지고 있으며 단일 리전의 각기 다른 가용 영역에 구성됩니다.스토리지는 3개의 가용 영역(AZ)에 걸쳐 있는 가상 디스크
kominjae.tistory.com
2024.07.06 - [공부/DATABASE] - [AWS] Aurora 공부 2 (Aurora의 기능들)
[AWS] Aurora 공부 2 (Aurora의 기능들)
Aurora의 블루그린 배포 메이저 버전의 업그레이드의 경우 스토리지와 컴퓨팅 영역이 분리된 Aurora의 특징으로 인하여 블루/그린 배포 방식을 통하여 진행이 가능하며 블루/그린 배포의 경우 (MySQ
kominjae.tistory.com
2024.09.15 - [공부/DATABASE] - [AWS] Aurora 공부 3 (모니터링)
[AWS] Aurora 공부 3 (모니터링)
Aurora 모니터링 도구들 클라우드 워치 Amazon Aurora에서 원시 데이터를 수집한 후 판독이 가능한 지표로 실시간에 가깝게 처리합니다Amazon Aurora는 기본적으로 1분 단위로 CloudWatch에 지표 데이터를
kominjae.tistory.com
Aurora의 블루그린 배포
메이저 버전의 업그레이드의 경우 스토리지와 컴퓨팅 영역이 분리된 Aurora의 특징으로 인하여 블루/그린 배포 방식을 통하여 진행이 가능하며 블루/그린 배포의 경우 (MySQL 기준)

BINLOG 설정 ON 으로 파라미터 변경을 위한 작업
GREEN 환경 생성 및 버전업그레이드, 배포 등 작업 진행과 에러 체크
점검시 Switch Over 를 통한 BLUE, GREEN 간 인스턴스 명칭 변경 진행
일정 시간 이후 이전 버전(기존 BLUE) 클러스터 삭제
순서로 작업을 진행할 수 있습니다.
블루/그린 사이의 복제 지연의 경우 하단의 방법으로 확인 가능합니다.
BLUE/GREEN 복제 지연 확인 방법
--MySQL
CluodWatch의 AuroraBinlogReplicaLag 지표 확인 해당 지표는 MySQL의 Seconds_Behind_Master 항목과 동일.
--postgreSQL lsn_distance 가 0일 경우 최신 복제본까지 처리 완료.
SELECT slot_name,
confirmed_flush_lsn as flushed,
pg_current_wal_lsn(),
(pg_current_wal_lsn() - confirmed_flush_lsn) AS lsn_distance
FROM pg_catalog.pg_replication_slots
WHERE slot_type = 'logical';
Amazon Aurora 리전 및 가용 영역
가용 영역의 경우 클러스터의 서브넷 그룹의 AZ 중 Aurora가 자동으로 3개의 AZ에 스토리지 복사본을 호스팅하며 해당 AZ 영역에 모든 DB 인스턴스가 생성이 됩니다.
Amazon Aurora에서 AWS 리전 및 Aurora DB 엔진별 지원 기능
Aurora 클러스터는 I/O-Optimized와 Standard 2개의 방식을 선택하여 구성이 가능합니다.
해당 부분은 서비스 런칭 전 미리 예측하기는 어려운 부분이 있습니다.
Standard로 생성 이후 서비스 운영을 진행하며 비용 중 I/O 사용량의 비용이 25%를 넘어간다면 비용 절감을 위해 변경을 검토해야 합니다.
Aurora 글로벌 데이터 베이스

Aurora 클러스터에서 다중 리전에 읽기 전용 보조 클러스터가 생성되어 데이터를 동기화 하는 기능입니다.
해당 동기화는 DB 엔진의 복제가 아닌 클러스터 스토리지 볼륨을 사용하여 진행됩니다.
최대 5개의 읽기 전용 보조 리전을 구성 가능합니다. FailOver가 발생하는 경우 보조 클러스터 리전이 Primary로 승격되나 EndPoint를 API에서 변경하는 작업이 필요합니다.
########2024-10-22 기준으로 글로벌 데이터베이스에 대한 Writer endpoint 기능이 추가되었습니다.
이제 글로벌 데이터베이스에서 하나의 리전에서 Down이 되어 Failover가 발생하여도 API에서는 새로운 클러스터 엔드포인트를 적용하여 배포해야하는 단계가 필요 없는 것으로 보입니다.
https://aws.amazon.com/about-aws/whats-new/2024/10/amazon-aurora-global-database-writer-endpoint/
RDS 프록시
어플리케이션과 DB의 연결에 대한 미들웨어 역할을 하는 RDS 프록시를 사용 가능합니다.
DB 커넥션 풀 관리와 DNS 캐시 문제를 해결하게 해줍니다.
장단점
- 장점
- DB Failover 발생 시 커넥션 지연 시간 감소 (평균 24 → 3 초)
https://aws.amazon.com/ko/blogs/database/improving-application-availability-with-amazon-rds-proxy/ - DB 커넥션 생성에 대한 리소스 소모 감소 (
- 다중 RO 환겨엥서 안정적인 로드밸런싱 가능 (RDS 의 경우 시분할 로드 밸런싱 )
https://repost.aws/knowledge-center/aurora-mysql-postgresql-reader-nodes
- DB Failover 발생 시 커넥션 지연 시간 감소 (평균 24 → 3 초)
- 단점
- 추가적인 네트워크 지연 발생
- DB 포트의 경우 기본 포트만 사용 가능
https://docs.aws.amazon.com/ko_kr/AmazonRDS/latest/UserGuide/rds-proxy-planning.html
ZDP
Aurora는 클라이언트의 DB 연결을 유지하며 버전을 업데이트 할 수 있는 기능을 제공합니다.
제약 사항으로는 다음과 같습니다.
지원되지 않는 업그레이드
- 운영 체제(OS) 패치 및 업그레이드
- 메이저 버전 업그레이드
ZDP에 제약이 생기는 작업.
- 장기간 쿼리 또는 트랜잭션이 진행 중인 경우 이 경우 Aurora가 ZDP를 수행할 수 있다면 열린 트랜잭션이 모두 취소됩니다.
- 임시 테이블 또는 테이블 잠금이 사용 중인 경우(예: DDL 문 실행 중) 이 경우 Aurora가 ZDP를 수행할 수 있다면 열린 트랜잭션이 모두 취소됩니다.
- 보류 중인 파라미터 변경 사항이 존재하는 경우
Aurora3 버전이 3.04.0보다 낮은 경우에서 SSL(보안 소켓 계층) 또는 전송 계층 보안(TLS) 연결이 존재하는 경우.
유사한 기능으로 제로 다운타임 리스타트 (ZDR)이 있습니다.
공식문서 설명 : 제로 다운타임 다시 시작(ZDR) 기능은 특정 종류의 다시 시작 중에 DB 인스턴스에 대한 활성 연결의 일부 또는 전부를 보관할 수 있습니다.
ZDR은 Aurora에서 오류 조건 (예: 복제본이 소스보다 너무 멀리 지연되기 시작하는 경우)을 해결하기 위해 자동으로 수행하는 다시 시작에 적용됩니다.
테스트 환경
RO 2개 생성
Custom EndPoint 생성하여 Replica 인스턴스 직접 호출
0.1초에 1번 4개 Endpoint로 select 구문 실행
테스트 결과로 해당 기능에 의존하여 마이너 버전 업그레이드를 중단 없이 실행하기에는 위험도가 높다고 판단됩니다.
Aurora MySQL 3.04.0 부터 순차 업그레이드 진행
| as is version |
to be version |
Error | Primary 콘솔 로그 특이사항 여부 | Replica01 콘솔 특이사항 로그 여부 | Replica02 콘솔 로그 특이사항 여부 |
| 3.04.0 | 3.04.1 | X | X | X | X |
| 3.04.1 | 3.04.2 | X | X | X | X |
| 3.04.2 | 3.04.3 | X | X | X | X |
| 3.04.3 | 3.06.1 | Primary, Custom Replica02 Endpoint |
O (Error 로그 발생) mysqlslap: Error when connecting to server: SSL connection error: error:00000001:lib(0)::reason(1) |
X | O (Restarted Error 로그 발생) mysqlslap: Error when connecting to server: SSL connection error: error:00000001:lib(0)::reason(1) mysqlslap: Error when connecting to server: Lost connection to MySQL server at 'reading initial communication packet', system error: 104 mysqlslap: Error when connecting to server: Can't connect to MySQL server on 'minjae-zdp-ro2.cluster-custom-cwgfom0rr1u3.ap-northeast-2.rds.amazonaws.com' (111) |
| 3.06.1 | 3.07 | X | X | O (Writer Instance 관련 에러 로그 발생) Read replica has been disconnected from the writer instance. |
X |
ZDR
Aurora DB 인스턴스 클래스
인스턴스 타입의 경우 R, T, X 타입이 사용이 가능합니다.
Amazon Aurora 스토리지 및 안정성
Aurora의 경우 클러스터 볼륨을 사용하며 6개의 데이터 사본으로 구성되어 있습니다.
하나의 데이터 사본에서 데이터 손실 또는 오류가 발생할 경우 다른 정상 데이터 사본을 통하여 해당 부분의 복구가 이루어 집니다.
클러스터의 경우 버전에 따라 최대 64 또는 128 테라의 용량을 사용할 수 있습니다.
스토리지는 10GB 단위로 증가되며 사용량 만큼의 비용이 발생합니다.
Aurora는 DB 인스턴스의 캐시가 데이터베이스와 별도의 프로세스로 관리되며 이로 인하여 인스턴스가 재시작되는 경우 케이스에 따라 캐시 웜업에 대한 이점이 있습니다.
예기치 않은 재시작 시 복구 방식
Aurora는 기본적으로 Binlog 없이도 예기치 않은 재시작에서 정상적으로 복구가 가능합니다.
다만 Aurora에서 Binlog가 활성화되어 있는 경우 DB 인스턴스는 Recovery 상황에서 바이너리 로그 복구를 강제적으로 수행하게되며 이는 복구 시간에 영향을 주게됩니다.
이를 빠르게 해소하기 위해 Aurora는 향상된 Binlog를 사용할 수 있습니다.
일반적인 Binlog의 쓰기 오버헤드는 최대 50%까지 증가할 수 있으며 향상된 Binlog는 바이너리 로그와 트랜잭션 로그를 스토리지에 병렬식으로 기록하는 방식으로 약 13%로 오버헤드를 감소 할 수 있습니다.
또한 Aorora MySQL은 3.05 버전부터 버퍼풀이 데이터베이스와 별도 프로세스로 분리되어 있는 점을 이용하여
재시작시 수행되는 일부 작업을 DB가 커넥션을 허용하는 단계 이후로 넘기고 잠금 구조의 메모리 할당을 최적화하여 연결 시간을 단축하였다고 합니다.
Aurora는 클러스터 볼륨이라는 특수한 구조를 가지고 운영이 되고 있으므로 DB Recovery에 대한 방식이 기존 커뮤니티 데이터베이스와는 다르다고 생각합니다.
공식 문서 기준
Primary 인스턴스가 Down이 발생하였을 때 Aurora는 다음의 2가지 방안을 중 하나를 선택한다.
- Replica 인스턴스를 Primary로 교체
- 신규 Primary 인스턴스 생성
운영 정책상 Replica 인스턴스가 1개 이상 존재하기 때문에 오로라는 1번 방식을 선택하고 대부분 30초 미만으로 복원이 되나 이 시간 동안은 읽기 및 쓰기 작업은 중단이 발생된다.
또한 동일한 우선순위를 가진 Replica 인스턴스가 여러개 존재하는 경우 크기가 큰 순서로 크기(인스턴스 타입의 크기를 의미한다)도 동일하다면 임의의 인스턴스를 선택하여 Primary로 승격시킵니다.
그렇다면 Primary 인스턴스에서 write 중 ACK를 못 받고 DB가 죽는다면 데이터 유실이 발생할지?
인스턴스가 다시 올라오면서 처리되지 않은 데이터에 대해 롤포워드를 진행하던 부분이 오로라에서는 어떻게 다를지?
내부적으로는 어떻게 될지 의문이 생겼습니다.
아래 내용은 명확히 확인이 되는 내용을 찾지 못하였고 공식 문서에서는 위에 내용 만으로 설명이 되어 있으므로 제가 이해한 내용을 바탕으로 추측하였습니다.
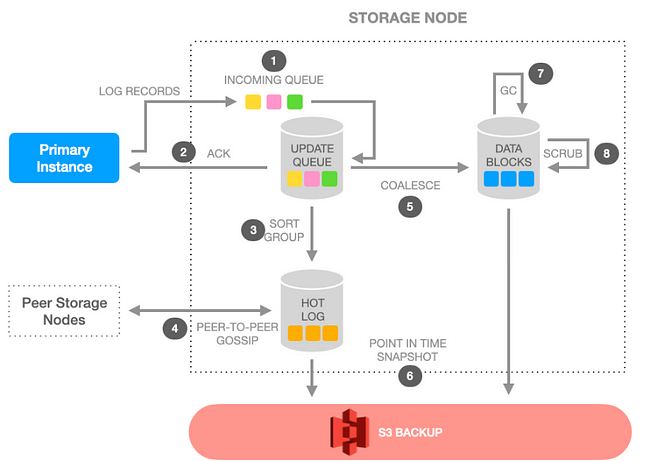
Aurora의 쓰기를 담당하는 Primary 인스턴스는 REDO 로그를 Incoming Queue에 넣고 Update Queue로 로그가 플러시되면 ACK를 받는데
- Incoming Queue에 있는 상태에서 Primary Node가 죽는 경우
해당 경우에는 Incoming queue에 있는 내용을 update queue에 넣고 새로운 Primary 인스턴스가 할당되면 Update Queue에 쌓인 LSN에 대하여 ACK를 넘겨 받으면서 데이터 정합성을 맞출 것 같습니다. (LSN은 Primary 인스턴스만 발급한다고 확인하였습니다). - ACK를 받은 상태에서 Primary Node가 죽는 경우
ACK를 이미 받은 상태에서는 DB 인스턴스와 스토리지 노드간의 분리된 영역인 점을 고려하면 비동기로 처리되는 쿼럼간 데이터 동기화 작업이 일어나며 데이터 유실이 발생하지 않을 것으로 판단됩니다.
→ 즉 기존 MySQL에서 발생하는 REDO LOG에 적용이 되었으나 데이터 파일에 동기화 되지 않은 부분을 위한 롤포워드는 따로 처리되지 않을 것으로 생각되며 해당 부분이 Aurora의 예기치 않은 재시작 시 복구 방법으로 생각됩니다 .
Aurora는 데이터베이스 오류 발생 후의 복구 시간을 어떻게 향상하나요?
다른 데이터베이스와 달리 데이터베이스 오류가 발생한 후 Amazon Aurora는 데이터베이스를 작업에 사용하기 전에 마지막 데이터베이스 검사점의 다시 실행 로그를 리플레이하여(대개 5분) 모든 변경 사항이 적용되었는지 확인할 필요가 없습니다. 따라서 대부분의 경우 데이터베이스 재시작 시간이 60초 미만으로 줄어듭니다.
Amazon Aurora는 데이터베이스 프로세스에서 버퍼 캐시를 이동하여 재시작 즉시 사용할 수 있도록 합니다. 이렇게 하면 캐시가 다시 채워질 때까지는 액세스를 제한할 필요가 없어 중단이 방지됩니다.
→ 바이너리 로그는 트랜잭션이 커밋되면 작성이 되기 때문에 바이너리 로그를 사용할 경우 추가적으로 세밀한 복원이 되는 것으로 생각됩니다.
PITR RPO 관련 내용
https://www.linkedin.com/pulse/achieve-5-minute-rpo-aws-rds-aurora-using-terraform-ashish-dadhich
AWS PITR 공식문서
https://docs.aws.amazon.com/ko_kr/AmazonRDS/latest/AuroraUserGuide/aurora-pitr.html
Aurora는 내부적으로 RPO 5분으로 시점 복원을 가능하게 합니다.
Amazon Aurora의 고가용성
Aurora 인스턴스의 고가용성
인스턴스 내의 Primary 인스턴스가 사용이 불가능하게 될 경우 복제 인스턴스 중 하나가 Primary 인스턴스로 변경됩니다.
글로벌 리전간의 고가용성
Primary 클러스터에서 FailOver가 발생하면 Secondary 클러스터가 Primary 클러스터로 승격됩니다.
다만 해당 과정에서 클러스터 엔드포인트가 변경이 발생합니다.
또한 Down 된 리전에 대해 스냅샷 생성 및 헬스체크를 진행하고 해당 리전이 정상적으로 사용이 가능해질 경우 자동으로 글로벌 클러스터에 보조 리전으로 다시 추가됩니다.
RDS 프록시를 사용하는 고가용성
Aurora에서 Failover 발생시에 엔드포인트에 새로 배정된 인스턴스의 IP를 맵핑하기 위한 DNS 쿼리 시간이 포함됩니다.
RDS 프록시를 사용하면 API는 RDS 프록시의 엔드포인트만을 알고 있으면 되며
Aurora에서 Failover가 발생할 경우에 RDS Proxy가 Primary로 승격된 인스턴스로 요청을 보내기 때문에 Aurora의 엔드포인트만을 사용한 경우 보다 빠르게 확인이 가능합니다.
Amazon Aurora를 사용한 복제
Aurora는 최대 15개의 복제 인스턴스를 생성할 수 있으며 만약 스토리지 복제 지연이 심하게 발생할 경우 내부적으로 해당 인스턴스를 재시작합니다.
MySQL 과 PostgreSQL의 네이티브 복제 기능을 활용하여 다른 리전의 Aurora 또는 EC2, Onpremise 환경의 DB에 데이터 동기화를 할 수 있습니다.
Aurora에 대한 DB 인스턴스 결제 (RI 개념이해)
온디맨드의 경우 사용량에 맞춰 비용을 지불하는 방식입니다.
RI 계약의 경우 리전, 엔진, 인스턴스 유형을 합쳐서 선계약하는 방식이며 1년 단위로 이루어지고 할인율은 상황에 따라 다릅니다.
Aurora Encryption 영향도 및 장단점
장점
보안에 대하여 쉽게 적용이 가능합니다.
어플리케이션에서 추가적인 작업이 없습니다.
성능에 대한 영향이 최소화 됩니다.
단점
KMS 관리와 백업, 복원, 로그 등의 작업에 추가적인 KMS 사용이 발생합니다.
입력 성능 테스트
단순 데이터 입력에서 약 2%의 CPU 상승 하였습니다. 그 외 QPS, Latency, Throughput 에서 의미있는 차이 확인되지 않았습니다.
Encryption ON





Encryption OFF





'공부 > DATABASE' 카테고리의 다른 글
| SQL Server, MySQL , PostgreSQL 플랜캐시 (0) | 2024.07.20 |
|---|---|
| [postgreSQL] 아키텍처와 Shared Buffer (0) | 2024.07.06 |
| [AWS] Aurora 공부 1 (아키텍처와 특징) (0) | 2024.07.04 |
| [SQL SERVER] 페이징 쿼리 (0) | 2024.06.19 |
| [SQL Server] 통계 업데이트와 쿼리 지연 (0) | 2024.06.14 |



