
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 램프 파이썬
- 백준 1238 파티 파이썬
- 베스트앨범 파이썬
- 프로그래머스 순위
- 프로그래머스 등굣길
- 백준 2352 반도체 설계 파이썬
- 백준 1034 램프 파이썬
- 백준 1043 거짓말 파이썬
- 백준 1613 역사
- 등굣길 파이썬
- 역사 파이썬
- SWEA
- 트리의 지름 파이썬
- 프로그래머스 베스트앨범
- 가장 긴 바이토닉 부분 수열 파이썬
- 프로그래머스 여행경로
- 반도체 설계 파이썬
- 프로그래머스 순위 파이썬
- 게임 개발 파이썬
- 가장 긴 팰린드롬 파이썬
- 다중 컬럼 NOT IN
- 백준 1516 게임 개발
- 다리 만들기 파이썬
- 프로그래머스 가장 긴 팰린드롬
- 백준 11054.가장 긴 바이토닉 부분 수열
- 백준 2146 다리 만들기
- SQL SERVER MIGRATION
- 순위 파이썬
- SQL SERVER 장비교체
- 백준 1167 트리의 지름 파이썬
- Today
- Total
공부, 기록
[AWS] Aurora 공부 1 (아키텍처와 특징) 본문
2024.07.04 - [공부/DATABASE] - [AWS] Aurora 공부 1 (아키텍처와 특징)
[AWS] Aurora 공부 1 (아키텍처와 특징)
1. 내부 아키텍처Aurora 는 클러스터 볼륨이라는 특수한 스토리지 구조를 가지고 있으며 단일 리전의 각기 다른 가용 영역에 구성됩니다.스토리지는 3개의 가용 영역(AZ)에 걸쳐 있는 가상 디스크
kominjae.tistory.com
2024.07.06 - [공부/DATABASE] - [AWS] Aurora 공부 2 (Aurora의 기능들)
[AWS] Aurora 공부 2 (Aurora의 기능들)
Aurora의 블루그린 배포 메이저 버전의 업그레이드의 경우 스토리지와 컴퓨팅 영역이 분리된 Aurora의 특징으로 인하여 블루/그린 배포 방식을 통하여 진행이 가능하며 블루/그린 배포의 경우 (MySQ
kominjae.tistory.com
2024.09.15 - [공부/DATABASE] - [AWS] Aurora 공부 3 (모니터링)
[AWS] Aurora 공부 3 (모니터링)
Aurora 모니터링 도구들 클라우드 워치 Amazon Aurora에서 원시 데이터를 수집한 후 판독이 가능한 지표로 실시간에 가깝게 처리합니다Amazon Aurora는 기본적으로 1분 단위로 CloudWatch에 지표 데이터를
kominjae.tistory.com
1. 내부 아키텍처
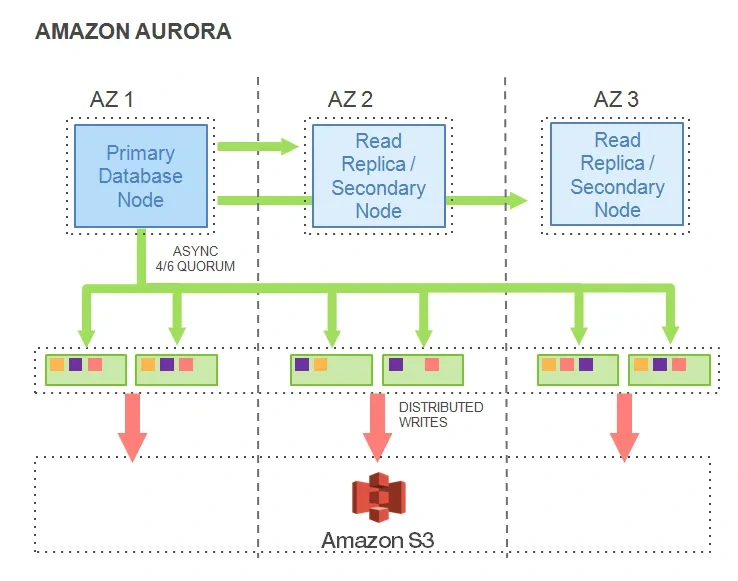


- Aurora 는 클러스터 볼륨이라는 특수한 스토리지 구조를 가지고 있으며 단일 리전의 각기 다른 가용 영역에 구성됩니다.
- 스토리지는 3개의 가용 영역(AZ)에 걸쳐 있는 가상 디스크 입니다.
- Aurora 는 데이터 동기화를 위해 Binlog를 사용하지 않습니다.
- 프라이머리 인스턴스의 경우 체크포인트, 더티페이지가 존재하지 않습니다.
- READ의 경우 요청에서 들어오는 LSN 값 그 이후의 데이터가 존재하는 스토리지의 읽기 노드로 요청을 보냅니다.
- 이 때 네트워크에서 가장 이점이 있는 데이터 블록에 접근하여 읽습니다.
- 데이터 동기화 방식
- Primary 인스턴스는 스토리지의 INCOMING Queue에 데이터 변경분에 대한 LOG를 전송합니다.
- UPDATE QUEUE에 플러시되면 PRIMARY 인스턴스에 ACK 전송합니다. (이로 인해 복제본 인스턴스가 느리게 작동하더라도 Primary 인스턴스가 ACK를 늦게 받지 않는다)
- DB 크래쉬 발생 시 UPDATE QUEUE가 많이 쌓인 상태에서 일부 인스턴스가 장애가 발생하면 이에 따른 RECOVERY가 지연된다
- 각 레코드에는 모두 LSN이 존재하고 볼륨 전체에 대해서 VCL (Volume Complete LSN) 이 있으며 이는 4/6 Quorum이 충족된 값이다. CPL (Consistency Pont LSN)은 가장 최근에 Commit된 LSN이고 장애가 발생하면 CPL 이후의 레코드는 롤백이 되며 복구가 진행된다.
- 위 작업이 끝나면 PRIMARY는 다른 작업을 수행할 수 있다.
- 비동기로 로그 레코드가 저장되었기 때문에 정렬과 그룹핑 작업을 통해 중복이 제거된 hot log를 생성합니다.
- 만약 로그 레코드에 빠진 데이터가 있다면 가십 프로토콜을 이용해 다른 스토리지 노드에게서 데이터를 받아옵니다.
- 최종적으로 redo 레코드를 데이터 페이지로 합치는 작업
- 주기적으로 redo 레코드와 데이터 페이지를 S3에 백업
- 로그 레코드가 백업 된 후 이전 버전에 대한 garbage collect 진행
- CRC 검사 수행
2. Aurora 의 다양한 기능
- Amazon Aurora에는 Aurora I/O-Optimized 및 Aurora Standard의 두 가지 DB 클러스터 스토리지 구성안으로 사용 가능합니다.
- I/O-Optimized는 I/O 요금이 별도 부과되지 않으나 GB당 용량이 STANDARD에 비해 2.25배 비쌈
- STANDARD의 I/O 요금은 100만 요청당 0.2달러
- I/O 작업은 모든 데이터베이스 페이지 읽기 작업은 1건의 I/O로 계산됩니다. WRITE는 4KB 단위로 계산, I/O 요청 사용량 확인 ->VolumeReadIOPs, VolumeWriteIOPs 지표
- Aurora DB 클러스터 데이터를 Amazon S3 버킷으로 내보낼 수 있습니다.
- Aurora DB 클러스터 스냅샷 데이터를 Amazon S3 버킷으로 내보낼 수 있습니다.
- Aurora Global Database는 다중 AWS 리전으로 확장할 수 있는 단일 데이터베이스 클러스터입니다 (특정 리전 전체의 장애 대응 가능).
- 블루/그린 배포가 가능합니다.
- 현재 환경(BLUE)의 복사본을 생성(GREEN)하여 배포하는 방법
- 10GB 단위로 스토리지가 자동 증가합니다.
3. 장점 (RDS, EC2 에 비하여)
- 일부 워크로드의 경우 Aurora은 기존 애플리케이션을 거의 변경하지 않고도 MySQL의 처리량을 최대 5배, PostgreSQL의 처리량을 최대 3배 제공할 수 있습니다(공식 문서 기준).
- REDO 로그 레코드만 작성되면 프라이머리 인스턴스는 다음 작업을 할 수 있기 때문에 기다리는 시간이 짧아 성능이 향상됩니다.
- Aurora 는 엔드포인트를 제공하여 더 편리하게 서비스에 제공할 수 있습니다.
- 클러스터 엔드포인트(라이터 인스턴스, mydbcluster.cluster ~~)
- 리더 엔드포인트(복제본 인스턴스, mydbcluster.cluster-ro~~, 기본 인스턴스만 있는 경우 해당 엔드포인트가 클러스터 엔드포인트와 동일한 기능으로 사용됨(라이터 가능))
- 사용자 지정 엔드포인트(최대 5개 생성 가능, 다양한 조건으로 설정 할 수 있다
EX) 특정 DB 파라미터 기준, 특정 사용자 그룹 등, myendpoint.cluster-custom~~) - 인스턴스 엔드포인트(클러스터의 특정 엔드포인트에 연결됨, mydbinstance~~)
- 신규 복제본을 생성할 때 데이터를 새로 복사하는 행위가 발생하지 않기 때문에 빠르게 생성이 가능하다.
- 컴퓨팅이 분리되어 있기에 캐시 웜업에 장점이 있다.
- 리더 인스턴스를 재부팅하지 않고 라이터 인스턴스를 재부팅할 수 있습니다.
- 라이터 인스턴스가 재부팅될 때 리더 인스턴스가 재부팅되지 않으면 페이지 캐시가 손실되지 않습니다.
- 라이터 인스턴스가 재부팅될 때 리더 인스턴스가 재부팅되면 페이지 캐시가 손실됩니다.
- 리더 인스턴스가 재부팅되면 라이터 및 리더 인스턴스의 페이지 캐시가 모두 유지됩니다.
- DB 클러스터가 장애 조치될 때 새 라이터 인스턴스에서는 페이지 캐시가 유지되지만, 리더 인스턴스(이전 라이터 인스턴스)에서는 페이지 캐시가 유지되지 않습니다.
4. 백업 및 복구 방법
- 지정된 시간에 자동 백업이 지원 됩니다
- Aurora에서 보존되는 백업 데이터, 이전에 저장한 DB 클러스터 스냅샷 또는 보존된 자동 백업에서 새 Aurora DB 클러스터를 생성하여 데이터를 복구할 수 있습니다.
- 백업 보존 기간 중 Aurora 백업은 연속 및 증분 방식으로 백업을 수행하므로 복원 시간을 줄이기 위해 데이터 스냅샷을 자주 캡처할 필요가 없습니다.
- DB 클러스터의 최근 복원 가능 시간은 일반적으로 활성 DB 클러스터의 경우 현재 시간으로부터 5분 이내, 보존된 자동 백업의 경우 클러스터 삭제 시간으로부터 5분 이내입니다.
- Aurora 복제본에 대해 장애 조치 우선 순위를 지정할 수 있습니다.
- 백트랙 기능을 사용하여 별도 인스턴스 생성 없이 특정 시점으로 인스턴스를 롤백할 수 있습니다 (추가 비용, 시간제약이 있음)
5. 제약사항
- 리전별 Aurora 클러스터는 40개까지 생성이 가능합니다 (요청을 통해 증가 가능).
- Aurora DB 클러스터는 기본 DB 인스턴스를 최대 15개까지 Aurora 복제본을 구성할 수 있습니다.
- Aurora 클러스터 볼륨 크기는 최대 128 (TiB)
- R타입, T타입, X타입만 사용 가능합니다. (최대 128vCPU, 1,024 GB, 40,000 스토리지 대역폭, 네트워크 50GBPS 최소 2vCPU 4GB 1,536 스토리지 처리량 네트워크 최대 5GBPS)
- DB 클러스터는 최대 7일간 중지할 수 있습니다. 7일이 경과한 후 DB 클러스터를 수동으로 시작하지 않으면 DB 클러스터가 자동으로 시작됩니다.
- Aurora 글로벌 데이터베이스의 일부인 클러스터는 중지 및 시작이 불가능합니다.
- 업그레이드 -> 마이너 버전은 자동 업그레이드를 NO로 설정할 수 있지만 필수 업그레이드의 경우에는 비 활성이되어 있어도 진행이 됩니다.
6. DR 발생시 시나리오
- 하나의 노드 장애 → 내부 페일오버가 발생하여 프라이머리 인스턴스가 변경 됨
- 하나의 AZ 장애 → 여러 AZ로 구성이 되어 있기 때문에 하나의 노드의 장애와 동일한 영향도
- AZ 전체 장애 → 별도 AZ 또는 리전에 스냅샷을 이용한 클러스터 생성이 필요
- 리전 장애 → 별도 리전에 데이터 동기화가 되어있지 않다면 DB 클러스터 스냅샷을 복사하여 생성 필요(제약 사항은 존재).
참조
아키텍처 관련
https://docs.aws.amazon.com/ko_kr/AmazonRDS/latest/AuroraUserGuide/CHAP_AuroraOverview.html
https://aws.amazon.com/ko/blogs/korea/amazon-aurora-under-the-hood-quorum-and-correlated-failure/
https://muratbuffalo.blogspot.com/2022/03/amazon-aurora-design-considerations-and.html
https://medium.com/garimoo/aws-aurora-%EC%95%84%ED%82%A4%ED%85%8D%EC%B2%98-6ff87b0d48c5
https://aws.amazon.com/ko/blogs/database/planning-i-o-in-amazon-aurora/
BACKTRACK 관련
블루그린배포 관련
https://www.slideshare.net/slideshow/d1s08lgaurora-bluegreen-deployment-upgradepdf/258850752
'공부 > DATABASE' 카테고리의 다른 글
| [postgreSQL] 아키텍처와 Shared Buffer (0) | 2024.07.06 |
|---|---|
| [AWS] Aurora 공부 2 (Aurora의 기능들) (0) | 2024.07.06 |
| [SQL SERVER] 페이징 쿼리 (0) | 2024.06.19 |
| [SQL Server] 통계 업데이트와 쿼리 지연 (0) | 2024.06.14 |
| [MySQL] 페이지 크래쉬 현상 (0) | 2024.06.10 |



