
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 다리 만들기 파이썬
- 프로그래머스 등굣길
- 백준 1167 트리의 지름 파이썬
- 등굣길 파이썬
- 프로그래머스 가장 긴 팰린드롬
- 가장 긴 팰린드롬 파이썬
- 역사 파이썬
- 백준 1613 역사
- 트리의 지름 파이썬
- 다중 컬럼 NOT IN
- 반도체 설계 파이썬
- 백준 2146 다리 만들기
- 백준 1516 게임 개발
- SQL SERVER 장비교체
- 백준 1043 거짓말 파이썬
- 프로그래머스 여행경로
- 프로그래머스 순위 파이썬
- SQL SERVER MIGRATION
- 백준 11054.가장 긴 바이토닉 부분 수열
- 게임 개발 파이썬
- 프로그래머스 순위
- SWEA
- 순위 파이썬
- 백준 1238 파티 파이썬
- 베스트앨범 파이썬
- 가장 긴 바이토닉 부분 수열 파이썬
- 프로그래머스 베스트앨범
- 램프 파이썬
- 백준 2352 반도체 설계 파이썬
- 백준 1034 램프 파이썬
- Today
- Total
공부, 기록
[SQL SERVER] 페이징 쿼리 본문
페이징 처리는 OLTP에서 매우 자주 사용되는 형식이다.
TOP, ROW_NUMBER, OFFSET NUM ROWS FETCH NEXT NUMS ROWS ONLY; 등 몇가지 방법이 있는데
이번 테스트에서는 OFFSET 구문을 통하여 실제로 페이징 처리를 통해서 I/O에서 이점이 발생하는 부분을 체크하고자 한다.
테스트 테이블 생성
CREATE TABLE TABLEA (COL1 INT, COL2 INT, COL3 DATETIME)
CREATE TABLE TABLEB (COL1 INT, COL2 INT, COL3 DATETIME)
SET NOCOUNT ON
DECLARE @NUM1 INT = 0
WHILE @NUM1 < 1000000
BEGIN
INSERT INTO TABLEA VALUES(@NUM1,@NUM1*10,GETDATE())
INSERT INTO TABLEB VALUES(@NUM1,@NUM1*10,GETDATE())
SET @NUM1 = @NUM1 + 1
END
--COL1에 CIX 생성 COL3 IX 생성
--TABLEA COL3에 500~2000 값 DATE값 변경
UPDATE TABLEA SET COL3 = DATEADD(DAY,3,GETDATE()) WHERE COL1 > 500 AND COL1 <= 2000
참고용.
정렬 없는 테이블 전체 조회.
SELECT * FROM TABLEA
테이블 'TABLEA'. 스캔 수 1, 논리적 읽기 3111
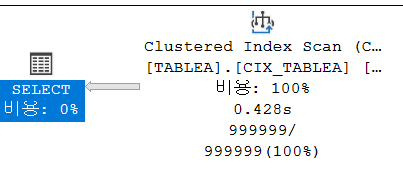
COL3 컬럼이 조건에 존재할 때 CLUSTERED INDEX SCAN이 아닌 해당 INDEX를 사용할 수 있도록 HINT를 적용하였다.
(스캔을 통한 조회를 테스트하고자함이 아니어서)
CASE 1 단일 테이블
CASE 1-1 조건 없는 조회
SELECT *
FROM TABLEA AS A
ORDER BY A.COL1 ASC OFFSET 0 ROWS FETCH NEXT 1000 ROWS ONLY;
테이블 'TABLEA'. 스캔 수 1, 논리적 읽기 9, 실제 읽기 2
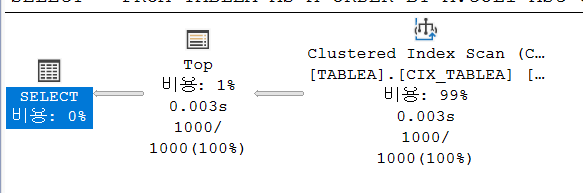
CASE 1-2 정렬과 관련 있는 조건 추가
SELECT *
FROM TABLEA AS A WITH (NOLOCK)
WHERE A.COL1 > 2000 AND A.COL1 < 4000
ORDER BY A.COL1 ASC OFFSET 0 ROWS FETCH NEXT 1000 ROWS ONLY;
테이블 'TABLEA'. 스캔 수 1, 논리적 읽기 7, 실제 읽기 2,
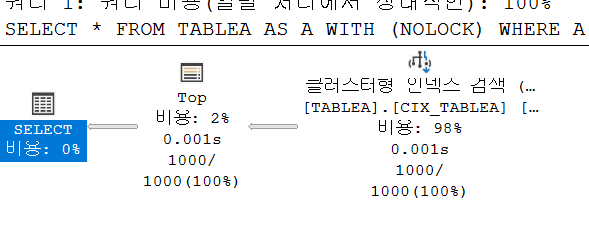
읽고자하는 1000개의 READ만 발생한
CASE 1-3 정렬 외 컬럼 조건 추가
SELECT *
FROM TABLEA AS A
WHERE COL3 > GETDATE()
ORDER BY A.COL1 ASC OFFSET 0 ROWS FETCH NEXT 1000 ROWS ONLY;
테이블 'TABLEA'. 스캔 수 1, 논리적 읽기 9

위 조건에서 CLUSTERED INDEX SCAN이 되었는데 만약 별도로 생성한 COL3의 인덱스를 강제하면 다음과 같은 결과가 나온다.
테이블 'Worktable'. 스캔 수 0, 논리적 읽기 0, 실제 읽기 0
테이블 'TABLEA'. 스캔 수 4, 논리적 읽기 4612, 실제 읽기 2
테이블 'Worktable'. 스캔 수 0, 논리적 읽기 0, 실제 읽기 0
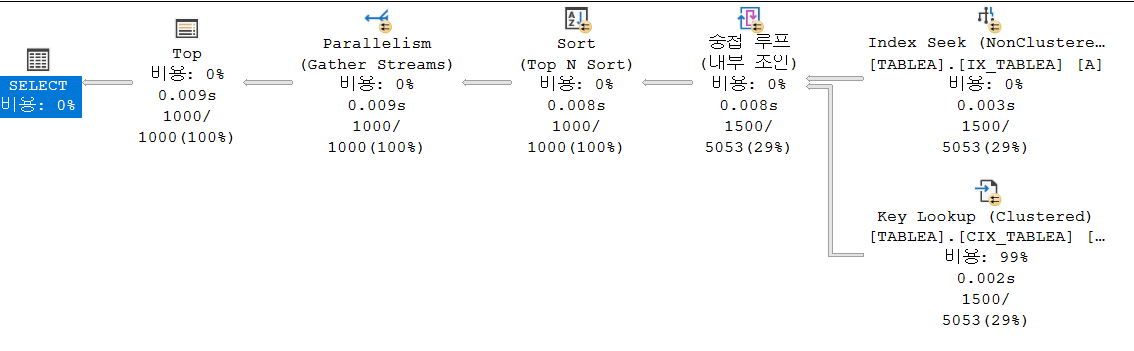
조건에 해당하는 데이터를 테이블에서 읽어온 후 SORT 와 TOP 과정이 진행되는 것을 볼 수 있다.
CASE 2 JOIN이 있는 2개의 테이블
CASE 2-1 조건이 없는 단순 조회
SELECT *
FROM TABLEA AS A
JOIN TABLEB AS B
ON A.COL1 = B.COL1
ORDER BY A.COL1 ASC OFFSET 0 ROWS FETCH NEXT 1000 ROWS ONLY;
테이블 'TABLEB'. 스캔 수 1000, 논리적 읽기 3219
테이블 'TABLEA'. 스캔 수 1, 논리적 읽기 10
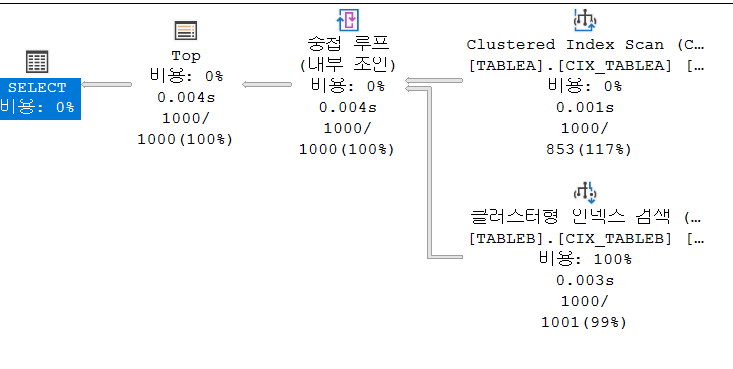
CASE 2-2 정렬 테이블에 정렬과 관련 있는 조건이 존재
SELECT *
FROM TABLEA AS A
JOIN TABLEB AS B
ON A.COL1 = B.COL1
WHERE A.COL1 > 2000 AND A.COL1 < 4000
ORDER BY A.COL1 ASC OFFSET 0 ROWS FETCH NEXT 1000 ROWS ONLY;
테이블 'TABLEB'. 스캔 수 1000, 논리적 읽기 3538
테이블 'TABLEA'. 스캔 수 1, 논리적 읽기 7
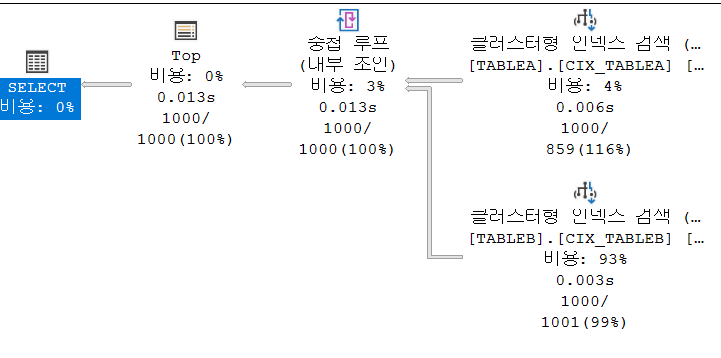
CASE 2-3 정렬 테이블에 정렬과 관련 없는 조건이 존재
SELECT *
FROM TABLEA AS A
JOIN TABLEB AS B
ON A.COL1 = B.COL1
WHERE A.COL3 > GETDATE()
ORDER BY A.COL1 ASC OFFSET 0 ROWS FETCH NEXT 1000 ROWS ONLY;
테이블 'Worktable'. 스캔 수 0, 논리적 읽기 0
테이블 'TABLEB'. 스캔 수 1046, 논리적 읽기 3365
테이블 'TABLEA'. 스캔 수 4, 논리적 읽기 4612
테이블 'Worktable'. 스캔 수 0, 논리적 읽기 0

CASE 2-4 비정렬 테이블에 정렬과 관련 있는 조건이 존재
SELECT *
FROM TABLEA AS A
JOIN TABLEB AS B
ON A.COL1 = B.COL1
WHERE B.COL1 > 2000 AND B.COL1 < 4000
ORDER BY A.COL1 ASC OFFSET 0 ROWS FETCH NEXT 1000 ROWS ONLY;
테이블 'TABLEB'. 스캔 수 1000, 논리적 읽기 3219
테이블 'TABLEA'. 스캔 수 1, 논리적 읽기 7
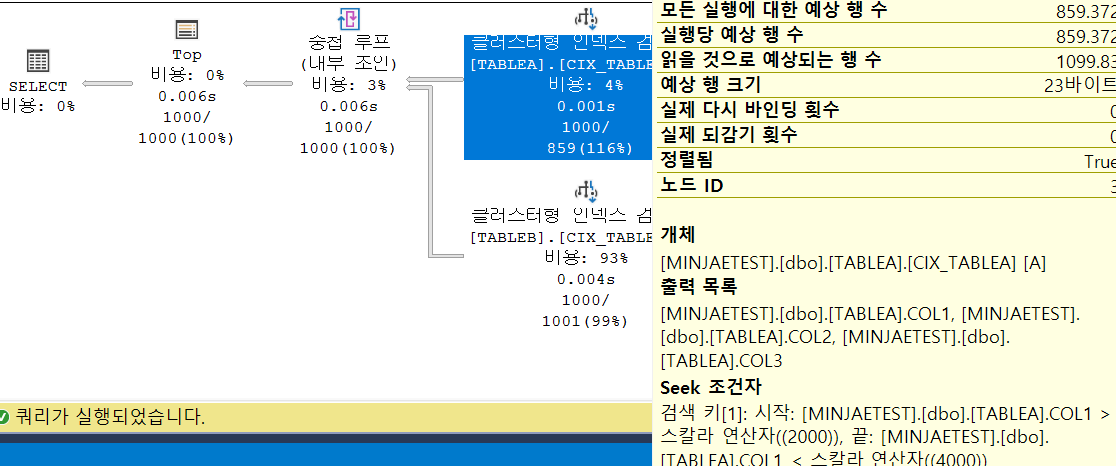
해당 케이스에서 특이한 점은 TABLEA 에서 TABLEB의 WHERE 조건이 반영이 되었다는 것이다.
옵티마이저가 INNER JOIN의 ON 조건으로 반영하여 처리하였다.
CASE 2-5 비정렬 테이블에 정렬과 관련 없는 조건이 존재
SELECT *
FROM TABLEA AS A
JOIN TABLEB AS B
ON A.COL1 = B.COL1
WHERE B.COL3 > GETDATE()
ORDER BY A.COL1 ASC OFFSET 0 ROWS FETCH NEXT 1000 ROWS ONLY;
테이블 'TABLEB'. 스캔 수 981595, 논리적 읽기 3136492
테이블 'TABLEA'. 스캔 수 5, 논리적 읽기 3164

TABLEB의 COL3에 대한 정보가 TABLEA에는 없기 때문에 테이블 스캔이 발생하고 JOIN을 하면서 TABLEB의 COL3 조건에 맞는 행만 가져오게 된다. 그 이후 TOP 쿼리 처리가 진행됨.
테스트를 통해 OFFSET 처리가 테이블과 WHERE 조건에 따라 일부만 읽거나 전체를 읽는 케이스가 발생한다는 것을 확인하였다.
다만 JOIN 컬럼과 WHERE 조건의 컬럼이 동일한 케이스였고 비교적 쿼리도 JOIN 테이블 수, 집계가 없는 등 심플한 케이스로 진행하여서 비약이 있을 수 있다고 생각이 든다. 검수간 쿼리를 확인과 실행계획 확인을 잘 하도록 해보자.
'공부 > DATABASE' 카테고리의 다른 글
| [AWS] Aurora 공부 2 (Aurora의 기능들) (0) | 2024.07.06 |
|---|---|
| [AWS] Aurora 공부 1 (아키텍처와 특징) (0) | 2024.07.04 |
| [SQL Server] 통계 업데이트와 쿼리 지연 (0) | 2024.06.14 |
| [MySQL] 페이지 크래쉬 현상 (0) | 2024.06.10 |
| [AWS Aurora PostgreSQL] 개념 공부 (0) | 2024.06.09 |



