
공부/DATABASE
[MySQL] 공부
무는빼주세요
2023. 5. 27. 16:04
Aurora/RDS MySQL, EC2차이
Aurora, RDS -> AWS의 관리형 서비스로 DB 인스턴스를 AWS가 관리 담당 -> 백업,복원, 자동 확장 등의 기능을 제공하여 관리에 편의를 줌 (관리형)
Aurora, RDS -> AWS의 관리형 서비스로 DB 인스턴스를 AWS가 관리 담당 -> 백업,복원, 자동 확장 등의 기능을 제공하여 관리에 편의를 줌 (관리형)
확장성
셋 모두 수평, 수직 확장이 가능 인스턴스 크기를 조정하거나 여러 인스턴스를 사용하여 성능 향상 가능
아키텍처
아키텍처
Aurora : 3개의 AZ로 구성되며 PRIMARY 노드에 WRITE가 진행이되면 6개의 저장소의 스토리지 노드에 REDO LOG(트랜잭션 로그)를 전달한다. 즉 WRITE 노드의 경우 체크포인트, 더티페이지가 존재하지 않음.
4곳에 저장이 되면 ACK를 받음.
READ는 네트워크에서 가장 이점이 있는 데이터 블록에 접근하여 읽음. 클라우드 네이티브 아키텍처로 분산 스토리지와 복제를 사용하여 더 높은 성능과 내구성을 제공
오로라는 BINLOG를 사용하지 않으므로 해당 기능만큼의 성능 향상이 있다. 처리량의 증가가 있으나 지연에 대한 성능 이점의 보장은 없음.
4곳에 저장이 되면 ACK를 받음.
READ는 네트워크에서 가장 이점이 있는 데이터 블록에 접근하여 읽음. 클라우드 네이티브 아키텍처로 분산 스토리지와 복제를 사용하여 더 높은 성능과 내구성을 제공
오로라는 BINLOG를 사용하지 않으므로 해당 기능만큼의 성능 향상이 있다. 처리량의 증가가 있으나 지연에 대한 성능 이점의 보장은 없음.
--> 2024/06/10 Aurora의 경우 데이터 저장이 좀 다르다.

각 레코드에는 모두 LSN이 존재하고 볼륨 전체에 대해서 VCL (Volume Complete LSN) 이 있으며 이는 4/6 Quorum이 충족된 값이다. CPL (Consistency Pont LSN)은 가장 최근에 Commit된 LSN이고 장애가 발생하면 CPL 이후의 레코드는 롤백이 되며 복구가 진행된다.
RDS, EC2 -> 전통적인 아키텍처로 단일 인스턴스에서 작동
가용성
RDS, EC2 -> 전통적인 아키텍처로 단일 인스턴스에서 작동
가용성
Aurora : 여러 가용 영역에 걸쳐 자동으로 데이터 복제하여 장애 복구와 내결함성을 강화
RDS : 복제를 통해 RO 형성 가능 장애 복구 기능은 X
EC2 : 수동으로 복제 구성 필요(MHA,MMM 등 추가 구성이 필요)
비용 : AURORA > RDS > EC2
이중화 방법 및 특징
Aurora : 자동 복제를 통해 이중화 구성. db 클러스터는 최소 2개의 인스턴스로 구성되며 write, ro 전용 복제본으로 구성된다.
Fast Clone 기능 -> 스토리지를 이미 사용하고 있으므로 해당 스토리지의 idbdata 파일, format 파일등만 신규 클러스터에 attach 해주므로 속도가 빠름 (mysql 을 신규로 올리는 정도의 시간만 소요)
그 이후 클론의 스토리지가 생성이 되며 기존, 클론간의 각각의 INSERT,DELETE 에 대한 독립성이 생김.
Backtrack 기능 지원(유료)
RDS : RO 복제본을 생성하여 구현 가능. 수동으로 복제본을 프로비저닝하고 관리해야함.
group replication 기능을 사용하여 구성할 수 있다.(오로라에서는 아직 불가능 2023/11/23)
optimized read/write 기능을 통하여 성능 향상 가능
(temp 테이블을 ebs에서 rds instance로 올림, AWS Nitro System 를 사용하여 이중버퍼 쓰기를 안하고 데이터를 플러싱)
EC2 : 복제 기능을 직접 사용하여야 함
설정
Aurora : AWS에서 관리하는 서비스로 AWS CLI를 사용. Aurora 클러스터의 경우 미리 정의된 클러스터 파라미터 그룹을 사용한다.
RDS : AWS에서 관리하는 서비스. RDS Console 또는 AWS CLI를 사용 하여 인스턴스 생성 및 구성 가능. rds 파라미터 그룹을 사용하여 인스턴스의 구성을 설정 가능.
EC2 : EC2 인스턴스에서 사용하는 경우 인스턴스를 직접 설정하고 구성해야 함.my.cnf를 수정하여 원하는 설정 가능.
백업 및 복원
Aurora : 자동 백업 지원. 지정된 시간에 자동으로 백업 수행. 해당 데이터로 Aurora 인스턴스 생성 가능.
RDS : 자동 백업 및 스냅샷 기능 제공. RDS 콘솔 또는 AWS CLI를 사용하여 설정 및 수동 복원 가능.
EC2 : 수동으로 구성 필요. MySQL 내장 도구를 사용하여 수행
RDS : 복제를 통해 RO 형성 가능 장애 복구 기능은 X
EC2 : 수동으로 복제 구성 필요(MHA,MMM 등 추가 구성이 필요)
비용 : AURORA > RDS > EC2
이중화 방법 및 특징
Aurora : 자동 복제를 통해 이중화 구성. db 클러스터는 최소 2개의 인스턴스로 구성되며 write, ro 전용 복제본으로 구성된다.
Fast Clone 기능 -> 스토리지를 이미 사용하고 있으므로 해당 스토리지의 idbdata 파일, format 파일등만 신규 클러스터에 attach 해주므로 속도가 빠름 (mysql 을 신규로 올리는 정도의 시간만 소요)
그 이후 클론의 스토리지가 생성이 되며 기존, 클론간의 각각의 INSERT,DELETE 에 대한 독립성이 생김.
Backtrack 기능 지원(유료)
RDS : RO 복제본을 생성하여 구현 가능. 수동으로 복제본을 프로비저닝하고 관리해야함.
group replication 기능을 사용하여 구성할 수 있다.(오로라에서는 아직 불가능 2023/11/23)
optimized read/write 기능을 통하여 성능 향상 가능
(temp 테이블을 ebs에서 rds instance로 올림, AWS Nitro System 를 사용하여 이중버퍼 쓰기를 안하고 데이터를 플러싱)
EC2 : 복제 기능을 직접 사용하여야 함
설정
Aurora : AWS에서 관리하는 서비스로 AWS CLI를 사용. Aurora 클러스터의 경우 미리 정의된 클러스터 파라미터 그룹을 사용한다.
RDS : AWS에서 관리하는 서비스. RDS Console 또는 AWS CLI를 사용 하여 인스턴스 생성 및 구성 가능. rds 파라미터 그룹을 사용하여 인스턴스의 구성을 설정 가능.
EC2 : EC2 인스턴스에서 사용하는 경우 인스턴스를 직접 설정하고 구성해야 함.my.cnf를 수정하여 원하는 설정 가능.
백업 및 복원
Aurora : 자동 백업 지원. 지정된 시간에 자동으로 백업 수행. 해당 데이터로 Aurora 인스턴스 생성 가능.
RDS : 자동 백업 및 스냅샷 기능 제공. RDS 콘솔 또는 AWS CLI를 사용하여 설정 및 수동 복원 가능.
EC2 : 수동으로 구성 필요. MySQL 내장 도구를 사용하여 수행
백업, 복원
Dump backup : 표준 도구로 SQL 쿼리를 생성하여 DB 개체와 해당 데이터를 TXT 파일로 추출(논리적 백업).
SQL 쿼리의 형태이므로 텍스트로 직접 확인 후 수정이 가능.
단일 스레드로 작동하므로 용량에 따라 시간 소요가 커진다.
복원을 하려면 백업 파일을 로드하여 SQL 쿼리를 실행해야 함.
Xtrabackup : MySQL 오픈소스 백업 도구. InnoDB와 XtraDB 스토리지 엔진의 경우에 빠른 백업과 복원 가능(물리적 백업).물리 레벨에서 DB 파일을 직접 백업 및 복원. 데이터 파일의 복사본이므로 따로 데이터를 읽거나 실행 X.
Master-Slave 환경에서도 사용 가능. 멀티 스레드로 작동하므로 속도가 더 빠름. 압축 옵션 제공.
사용방법
MySQL Dump:
MySQL 공식 문서: https://dev.mysql.com/doc/refman/8.0/en/backup-and-recovery.html
MySQL 공식 문서: https://dev.mysql.com/doc/refman/8.0/en/mysqldump.html
MySQL Tutorial: How to Use mysqldump
XtraBackup:
Percona XtraBackup 공식 문서: https://www.percona.com/software/documentation
Percona XtraBackup GitHub: https://github.com/percona/percona-xtrabackup
Percona XtraBackup 커뮤니티 포럼: https://forums.percona.com/c/mysql-mariadb/percona-xtrabackup/10
Percona XtraBackup 공식 문서: https://www.percona.com/software/documentation
Percona XtraBackup GitHub: https://github.com/percona/percona-xtrabackup
Percona XtraBackup 커뮤니티 포럼: https://forums.percona.com/c/mysql-mariadb/percona-xtrabackup/10
Online DDL : 스키마의 변경 작업을 하며 read/write가 필요할 때 사용 가능.특징
대규모 트래픽 환경 : 데이터베이스에 지속적인 읽기 및 쓰기 작업이 발생하는 경우, 일시적으로 데이터베이스를 비활성화하거나 다운타임을 최소화해야 할 수 있습니다. Online DDL을 사용하면 스키마 변경을 수행하면서도 서비스의 지속적인 가용성을 유지할 수 있습니다.
데이터 일관성 요구 사항 : 일반적으로 스키마 변경 작업은 데이터베이스를 잠시 중단시켜야 하기 때문에 해당 작업 동안 발생하는 트랜잭션은 중단될 수 있습니다. 그러나 Online DDL을 사용하면 스키마 변경 작업 도중에도 트랜잭션을 계속해서 처리할 수 있으므로 데이터 일관성을 유지할 수 있습니다.
긴 작업 시간 : 스키마 변경 작업이 많은 시간이 걸리는 경우, 다운타임을 최소화하고 서비스의 가용성을 유지하기 위해 Online DDL을 사용할 수 있습니다. 이는 대량 데이터 마이그레이션, 인덱스 생성 또는 삭제, 테이블 재구성 등과 같은 작업에서 특히 유용합니다.
Native Online DDL은 스토리지 엔진을 기반으로 하며 스키마가 변경되는 동안 인입되는 DML을 임시 버퍼(캐시)에 기록한다. ( innodb_online_alter_log_max_size 값으로 로그 사이즈 조정이 가능) 스키마 변경이 완료가 되면 버퍼의 내용을 순서대로 적용하는 방식으로 처리된다. 명령어 마다 동작하는 알고리즘이 다르며 INSTANT, INPLACE, COPY 순으로 무거운 작업.
pt-online-change-schema
Percona Toolkit에서 제공하는 Online DDL 툴
Native Online DDL 과의 차이는
- 신규 테이블을 생성하고 스키마 변경 사항이 적용된다.
- 인입 데이터의 경우 트리거에 의해서 신규 테이블에 적용이 된다
- 그 이후 신규 테이블과 기존 테이블과의 데이터 동기화가 chunk-size만큼 혹은 unique key 단위로 이루어지며
- 변경이 완료될 경우 테이블은 스위칭 된다.
아래와 같은 옵션 설정이 가능.
- --no-drop-old-table : 마이그레이션 후, 기존 테이블을 삭제 하지 않음.
- host, port, user : 스크립트를 실행할 대상 DB 정보.
- chunk-size : 한번에 복사할 데이터양.
- --charset=UTF8 : 캐릭터 셋 설정
- --alter-foreign-keys-method=auto :FK도 복사할것인지 여부. 옵션값이 auto일 경우 최적화된 방식으로 FK를 복사.
- max-lag : pt-osc는 master에서만 작업할 수 있는데 slave에서 복제지연이 발생하면 pt-osc 작업을 중단하고 기다림
- max-load : 작업 도중 서버에 과한 load 를 막기위해 수행하는 세션이 일정 수치 이상 되면 pt-osc 작업 일시 중지함
- critical-load : max-load가 일시정지라면 이 옵션은 pt-osc 작업 중단시킴
- set-vars: pt-osc 작업 시작할 때 설정할 세션 설정 값 (격리수준, 락타임아웃 시간 등)
- no-check-alter : alter DDL 구문 체크
- recursion-method : db port가 기본 port (3306)이 아닐 때 Slave를 찾기위한 설정.
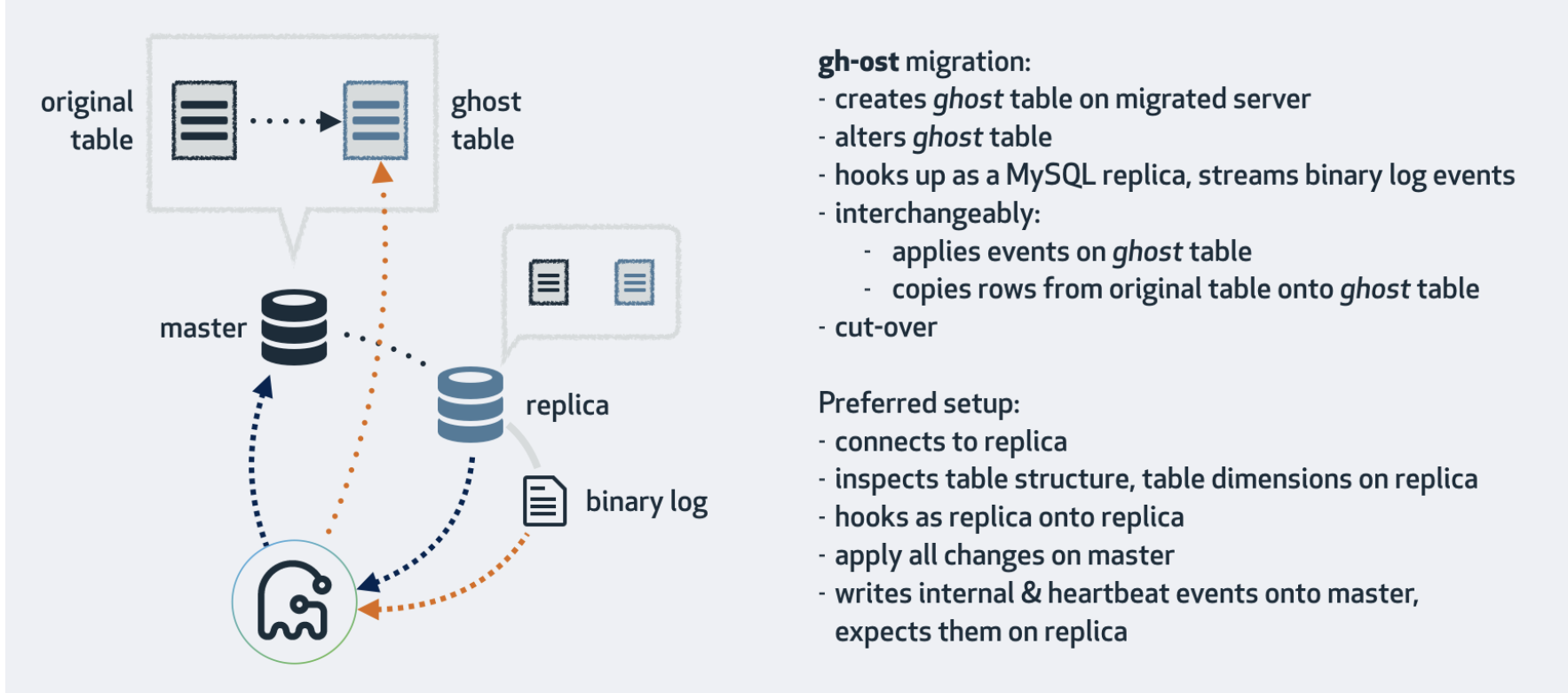
gh-ost
GitHub에서 MysSQL 스키마 변경을 위해 만들어진 오픈소스
- 원본 테이블과 카피 테이블을 생성
- 기존 테이블의 PK로 chunk-size 데이터를 카피
- DML에 대해 binlog 스트림을 사영하여 카피 테이블에 반영
- 완료 시 테이블 스위칭
3번의 동작 방식 덕분에 gh-ost는 다음과 같은 이점 및 설정을 해야한다.
- master 서버에서 수행된 DML에 대한 binary log를 ghost table에 반영함
- binary log를 가져올 서버는 log-bin, binlog-format=ROW 설정 필요
- SLAVE에서 가져오는 경우엔 log_slave_updates 옵션도 추가로 필요함
- triggerless 방식으로 트리거에 의한 부하가 없으며 작업 일시정지가 자유로움
설정 매개변수
- host : binary log 를 가져올 서버 설정
- throttle-control-replicas : –max-lag-millis 를 체크할 리플리카 서버 지정하는 옵션
- switch-to-rbr : gh-ost 는 binlog_format=ROW 일 때만 동작하기 때문에 작업 대상 서버의 binlog_format을 ROW로 변경하는 옵션. 주로 Slave의 binlog_format 변경과 log_slave_updates 옵션 설정 후 재기동 수행 (원복 X)
- allow-master-master : MMM 사용할 때 처럼 master-master (active-passive) 구성일 때 설정
- allow-on-master : master에서 작업할 때 설정하는 옵션
- migrate-on-replica : slave 에서 작업할 때 설정하는 옵션
- assume-master-host : allow-master-master 설정 시 작업할 master 서버 지정하는 옵션
- cut-over : 테이블 스위칭하는 마지막 단계 방식
- panic-flag-file : gh-ost를 중지하기 위한 방법으로 flag-file 생성 시 작업이 취소된다.
- postpone-cut-over-flag-file : flag-file 존재하면 cut-over 단계를 수행하지 않고 대기함 이 옵션 설정 시 작업 시작 할때 이 파일을 생성하기 때문에 마지막 rename 단계 전에 수동으로 삭제해줘야함. 대기하더라도 DML은 계속 copy 진행됨
- throttle-flag-file : throttle-flag-file 존재하면 작업 일시정지
- alter : 스키마 변경 구문
복제
주로 끌어오기 방식으로 슬레이브에서 마스터의 바이너리 로그를 읽고 변경 부분에 대하여 동기화 한다.
마스터(Master) : 변경 사항이 발생하는 데이터베이스 서버. 마스터 서버는 이벤트를 생성하고 이를 바탕으로 바이너리 로그(Binary Log)에 기록.
슬레이브(Slave) : 마스터 서버의 변경 사항을 복제하는 데이터베이스 서버. 슬레이브 서버는 마스터 서버로부터 바이너리 로그 이벤트를 읽어와 슬레이브의 데이터베이스를 동기화.
바이너리 로그(Binary Log) : 마스터 서버에서 생성되는 이벤트를 기록하는 로그 파일. 이 로그 파일은 마스터 서버의 변경 사항을 슬레이브 서버로 전달하는 데 사용 (복원에도 사용된다).
복제 스레드(Replication Threads) : 슬레이브 서버에는 I/O 스레드와 SQL 스레드로 구성된 두 가지 복제 스레드가 있다.
- I/O Thread
복제 작업 중 마스터 서버로부터 변경 로그(바이너리 로그)를 읽어 오는 작업을 한다. 복제 지여 또는 I/O Thread의 오류가 발생하면 복제 작업의 중지가 생길 수 있다. - SQL Thread
I/O Thread로 부터 전달받은 변경 로그를 슬레이브에 적용하는 역할. 마스터 서버와의 네트워크 연결이 필요하지 않으며 슬레이브 서버내에서만 작업이 이루어진다. 복제 작업 중 SQL Thread에서 오류가 발생하면 해당 작업이 중지되며 이후 변경 로그부터 복제 작업이 시작 됨.
복제 지연(Lag) : 슬레이브 서버는 마스터 서버와의 네트워크 지연이나 처리 시간 등으로 인해 일시적으로 데이터 복제가 지연되는 경우가 발생할 수 있으며 이를 복제 지연이라고 함(Seconds Behind Master 값으로 모니터링 가능).
바이너리 로그는 Statement-Based Format (SBR)와 Row-Based Format (RBR) 두가지 방식이 있으며(둘을 섞은 MIXED도 존재)
바이너리 로그는 Statement-Based Format (SBR)와 Row-Based Format (RBR) 두가지 방식이 있으며(둘을 섞은 MIXED도 존재)
SBR은 SQL 쿼리 자체를 기록한다.이 포맷은 SQL 문장의 실행 결과가 항상 동일하다는 가정을 한다.
따라서 동일한 SQL 문장이 여러 번 실행되더라도 결과가 항상 일치해야 한다.
따라서 동일한 SQL 문장이 여러 번 실행되더라도 결과가 항상 일치해야 한다.
SBR은 로그 크기가 작아지는 장점이 있지만, 복제 시에 데이터 일관성을 보장하기 위해 추가적인 로깅이 필요할 수 있다.
RBR은 SQL 문장 대신 변경된 데이터의 실제 행(row)을 로그에 기록.
RBR은 SQL 문장에 의존하지 않고 변경된 데이터 자체를 기록하기 때문에 문장 실행 결과와 관계없이 데이터의 일관성을 보장.
RBR은 SBR보다 로그 크기가 크지만, 더 정확한 변경 사항을 기록하기 때문에 데이터 일관성을 보다 강력하게 보장할 수 있다.
RBR은 SQL 문장에 의존하지 않고 변경된 데이터 자체를 기록하기 때문에 문장 실행 결과와 관계없이 데이터의 일관성을 보장.
RBR은 SBR보다 로그 크기가 크지만, 더 정확한 변경 사항을 기록하기 때문에 데이터 일관성을 보다 강력하게 보장할 수 있다.
복제 옵션
병렬 복제 : 복제를 병렬로 처리하는 것. 성능 측면에서는 향상되나 병렬로 처리되는 작업 간의 순서와 동기화에 신경써주어야 하며 트랜잭션 일관성 유지를 위해 추가적인 설정이 필요할 수 있다.
세미싱크 : 복제의 일관성을 위하여 사용되는 기능.
MySQL 복제는 비동기 복제방식으로 동작하므로 Master에서 변경된 데이터를 Slave로 전송하며 마스터가 변경 사항을 적용하는 동안 슬레이브는 이를 대기하지 않고 다음 작업을 수행하므로 일관성에 지연이 발생할 수 있음.
세미 싱크 복제에서는 슬레이브 서버가 마스터 서버로부터 변경 사항을 수신한 후에 반드시 마스터 서버로부터 확인 응답을 받아야 함. 이 응답은 마스터 서버가 변경 사항을 로그에 기록하고 커밋까지 했다는 의미.
세미 싱크 과정
1. 마스터 서버에서 변경 사항이 발생하면 변경 사항을 슬레이브 서버로 전송.
2. 슬레이브 서버는 변경 사항을 수신하고 로그에 기록.
3. 슬레이브 서버는 마스터 서버로부터 확인 응답을 요청.
4. 마스터 서버는 변경 사항을 로그에 기록하고 커밋한 후, 확인 응답을 슬레이브 서버에게 전송.
5. 슬레이브 서버는 확인 응답을 받은 후에야 다음 작업을 수행.
세미 싱크는 일관성은 향상되나 이에 따라 복제 지연이 발생할 수는 있다.
세미싱크 : 복제의 일관성을 위하여 사용되는 기능.
MySQL 복제는 비동기 복제방식으로 동작하므로 Master에서 변경된 데이터를 Slave로 전송하며 마스터가 변경 사항을 적용하는 동안 슬레이브는 이를 대기하지 않고 다음 작업을 수행하므로 일관성에 지연이 발생할 수 있음.
세미 싱크 복제에서는 슬레이브 서버가 마스터 서버로부터 변경 사항을 수신한 후에 반드시 마스터 서버로부터 확인 응답을 받아야 함. 이 응답은 마스터 서버가 변경 사항을 로그에 기록하고 커밋까지 했다는 의미.
세미 싱크 과정
1. 마스터 서버에서 변경 사항이 발생하면 변경 사항을 슬레이브 서버로 전송.
2. 슬레이브 서버는 변경 사항을 수신하고 로그에 기록.
3. 슬레이브 서버는 마스터 서버로부터 확인 응답을 요청.
4. 마스터 서버는 변경 사항을 로그에 기록하고 커밋한 후, 확인 응답을 슬레이브 서버에게 전송.
5. 슬레이브 서버는 확인 응답을 받은 후에야 다음 작업을 수행.
세미 싱크는 일관성은 향상되나 이에 따라 복제 지연이 발생할 수는 있다.
시스템디비
간략하게는
mysql : 유저 정보, 권한 정보, 접속 기록 등을 포함하여 서버의 사용자 관리와 보안을 관리
information_schema : 데이터베이스, 테이블, 컬럼 등의 스키마 정보를 제공하며 실행 계획, 통계 정보등도 확인.
performace_schema : MySQL 서버의 성능 모니터링과 관련된 정보를 제공. 쿼리 실행시간, 블락 종버, 인덱스 사용 통계 등의 정보 확인.
information_schema : 데이터베이스, 테이블, 컬럼 등의 스키마 정보를 제공하며 실행 계획, 통계 정보등도 확인.
performace_schema : MySQL 서버의 성능 모니터링과 관련된 정보를 제공. 쿼리 실행시간, 블락 종버, 인덱스 사용 통계 등의 정보 확인.
자세하게는
mysql 디비:
사용자 계정과 권한 정보, 접속 기록 등을 관리.
사용자 계정 생성, 권한 부여, 비밀번호 변경 등의 작업을 수행.
관리자가 MySQL 서버에 대한 보안 및 접근 제어를 설정하는 데 사용.
mysql 디비:
사용자 계정과 권한 정보, 접속 기록 등을 관리.
사용자 계정 생성, 권한 부여, 비밀번호 변경 등의 작업을 수행.
관리자가 MySQL 서버에 대한 보안 및 접근 제어를 설정하는 데 사용.
information_schema 디비:
MySQL 데이터베이스 서버의 메타데이터를 제공.
데이터베이스, 테이블, 컬럼, 인덱스 등의 스키마 정보를 조회.
쿼리 실행 계획, 통계 정보, 사용자 권한 정보 등을 제공.
MySQL 데이터베이스 서버의 메타데이터를 제공.
데이터베이스, 테이블, 컬럼, 인덱스 등의 스키마 정보를 조회.
쿼리 실행 계획, 통계 정보, 사용자 권한 정보 등을 제공.
performance_schema 디비:
MySQL 서버의 성능 모니터링과 관련된 정보를 제공.
쿼리 실행 시간, 블록된 트랜잭션, 인덱스 사용 통계 등을 조회.
성능 분석 및 최적화를 위한 정보를 제공.
MySQL 서버의 성능 모니터링과 관련된 정보를 제공.
쿼리 실행 시간, 블록된 트랜잭션, 인덱스 사용 통계 등을 조회.
성능 분석 및 최적화를 위한 정보를 제공.
기본명령어들
show processlist - MS의 who2랑 거의 유사
show processlist - MS의 who2랑 거의 유사
lock 확인
SHOW ENGINE INNODB STATUS : InnoDB 스토리지 엔진에 대한 상세한 정보를 제공합니다. 이 중간에 "LATEST DEADLOCK" 섹션을 찾을 수 있으며, 여기에는 최근 데드락(Deadlock) 발생에 관련된 정보가 포함됩니다. 데드락이 발생하지 않은 경우에도 "SEMAPHORES" 섹션 아래에 Lock 정보가 표시.
INFORMATION_SCHEMA.LOCKS : LOCKS 테이블은 현재 사용 중인 Lock 정보를 포함.
SHOW FULL PROCESSLIST : 현재 실행 중인 모든 쿼리와 클라이언트 세션 정보를 출력. Lock이 발생한 경우 해당 쿼리가 실행 중인 클라이언트 세션을 확인 가능.
Performance Schema를 사용한 Lock 모니터링: Performance Schema는 MySQL의 성능 모니터링을 위한 기능을 제공하는 스키마. Performance Schema를 활성화하고 적절한 이벤트 필터를 설정하여 Lock 관련 이벤트를 모니터링할 수 있다. 이를 통해 Lock이 발생하는 테이블, 쿼리, 세션 등의 상세 정보를 확인할 수 있다.
show variales : MySQL 서버의 현재 구성 변수 및 값을 확인하는 명령 (파일 경로, 버퍼 크기, 쿼리 캐시 설정 등) SHOW VARIABLES LIKE '~~'; 명령어로 특정 값 확인 가능. 주로 서버 구성을 튜닝하는데 사용.
SHOW ENGINE INNODB STATUS : InnoDB 스토리지 엔진에 대한 상세한 정보를 제공합니다. 이 중간에 "LATEST DEADLOCK" 섹션을 찾을 수 있으며, 여기에는 최근 데드락(Deadlock) 발생에 관련된 정보가 포함됩니다. 데드락이 발생하지 않은 경우에도 "SEMAPHORES" 섹션 아래에 Lock 정보가 표시.
INFORMATION_SCHEMA.LOCKS : LOCKS 테이블은 현재 사용 중인 Lock 정보를 포함.
SHOW FULL PROCESSLIST : 현재 실행 중인 모든 쿼리와 클라이언트 세션 정보를 출력. Lock이 발생한 경우 해당 쿼리가 실행 중인 클라이언트 세션을 확인 가능.
Performance Schema를 사용한 Lock 모니터링: Performance Schema는 MySQL의 성능 모니터링을 위한 기능을 제공하는 스키마. Performance Schema를 활성화하고 적절한 이벤트 필터를 설정하여 Lock 관련 이벤트를 모니터링할 수 있다. 이를 통해 Lock이 발생하는 테이블, 쿼리, 세션 등의 상세 정보를 확인할 수 있다.
show variales : MySQL 서버의 현재 구성 변수 및 값을 확인하는 명령 (파일 경로, 버퍼 크기, 쿼리 캐시 설정 등) SHOW VARIABLES LIKE '~~'; 명령어로 특정 값 확인 가능. 주로 서버 구성을 튜닝하는데 사용.
show status : MySQL의 상태 정보와 해당 값이 나열된다(쿼리 수행 횟수, 연결 수, 버퍼 히트율, 잠금 충돌 등) SHOW VARIABLES 와 마찬가지로 LIKE 명령어 사용 가능. 주로 성능 모니터링과 퍼포먼스 분석에 유용.
show engine innodb status : INNODB 스토리지 엔진의 상태 정보를 확인하는 명령어.
주요 섹션
- SEMAPHORES: InnoDB 스토리지 엔진의 세마포어 정보를 표시합니다. 이 섹션에서는 InnoDB가 현재 사용 중인 세마포어의 상태와 대기 중인 세마포어의 수 등을 확인할 수 있습니다.
- TRANSACTIONS: 현재 실행 중인 트랜잭션의 상태와 정보를 보여줍니다. 이 섹션에서는 각 트랜잭션의 ID, 상태, 시작 시간, 대기 중인 Lock 정보 등을 확인할 수 있습니다.
- FILE I/O: InnoDB 스토리지 엔진의 파일 I/O 작업과 관련된 정보를 제공합니다. 이 섹션에서는 데이터 파일과 로그 파일에 대한 I/O 작업 수행 상태와 통계 정보를 확인할 수 있습니다.
- BUFFER POOL AND MEMORY: InnoDB 스토리지 엔진의 버퍼 풀과 메모리 사용에 관련된 정보를 표시합니다. 이 섹션에서는 버퍼 풀 크기, 버퍼 히트율, 메모리 사용량 등을 확인할 수 있습니다.
- ROW OPERATIONS: InnoDB 스토리지 엔진의 행 조작 작업에 관련된 정보를 제공합니다. 이 섹션에서는 삽입, 갱신, 삭제 작업의 수행 상태와 통계 정보를 확인할 수 있습니다.
PERFORMACE COUNTERS
MYSQL // SQL SERVER
innodb_buffer_pool_reads // page lookups/sec
queries/sec // batch requests/sec
cpu
Handler : DB서버 내부에서 발생하는 작업을 처리하는 핸들러 개체. 다양한 작업 유형을 처리하며 테이블과 인덱스를 쓰고 읽는 작업을 포함한다. 클라이언트로부터 전송된 SQL 쿼리는 Handler에 의해 처리됨. Handler는 쿼리의 실행 계획에 따라 데이터에 접근하고 테이블과 인덱스에서 필요한 데이터를 읽거나 쓴다. 또한 데이터를 버퍼에 저장하고 처리한다. 즉 MySQL 데이터베이스 엔진 내부에서 작동하며, 클라이언트의 요청에 따라 데이터베이스 작업을 처리. 핸들러는 데이터의 읽기, 쓰기, 인덱스 접근 등과 관련된 작업을 수행하여 데이터베이스 서버의 성능과 작업 부하를 조절하는 데 중요한 역할.
innodb_buffer_pool_reads // page lookups/sec
queries/sec // batch requests/sec
cpu
Handler : DB서버 내부에서 발생하는 작업을 처리하는 핸들러 개체. 다양한 작업 유형을 처리하며 테이블과 인덱스를 쓰고 읽는 작업을 포함한다. 클라이언트로부터 전송된 SQL 쿼리는 Handler에 의해 처리됨. Handler는 쿼리의 실행 계획에 따라 데이터에 접근하고 테이블과 인덱스에서 필요한 데이터를 읽거나 쓴다. 또한 데이터를 버퍼에 저장하고 처리한다. 즉 MySQL 데이터베이스 엔진 내부에서 작동하며, 클라이언트의 요청에 따라 데이터베이스 작업을 처리. 핸들러는 데이터의 읽기, 쓰기, 인덱스 접근 등과 관련된 작업을 수행하여 데이터베이스 서버의 성능과 작업 부하를 조절하는 데 중요한 역할.
- Handler_read_first: 테이블에서 첫 번째 레코드를 읽는 핸들러의 수. 이는 인덱스를 사용하지 않고 테이블의 첫 번째 레코드를 검색하는 경우에 해당.
- Handler_read_key: 인덱스를 사용하여 행을 읽는 핸들러의 수. 이는 WHERE 절에 인덱스를 사용한 조회 작업에서 발생. 인덱스 컬럼과 일치하는 행을 검색할 때 사용.
- Handler_read_next: 인덱스를 사용하여 다음 행을 읽는 핸들러의 수. 이는 인덱스 순회나 범위 검색 작업에서 발생.
- Handler_read_prev: 인덱스를 사용하여 이전 행을 읽는 핸들러의 수. 이는 역방향 인덱스 순회나 범위 검색 작업에서 사용될 수 있다.
- Handler_read_rnd: 임의의 위치에서 행을 읽는 핸들러의 수. 일부 쿼리는 인덱스를 사용하지 않거나 임의의 위치에서 행을 읽는 작업이 필요한 경우에 해당. 이는 테이블 스캔 작업이나 임의의 순서로 행을 읽는 작업에서 발생.
- Handler_read_rnd_next: 임의의 위치에서 다음 행을 읽는 핸들러의 수. 이는 임의의 위치에서 행을 읽은 후에 다음 행을 계속해서 읽는 작업에 사용.
- Handler_write: 행을 삽입, 갱신 또는 삭제하는 핸들러의 수.
- Handler_commit: 커밋된 트랜잭션 수.
- Handler_rollback: 롤백된 트랜잭션 수.
- 테이블 스캔 -> read_key, read_first, read_rnd_next 증가
- pk 1건 조회 → read_key 증가
- index 조회 + 인덱스 컬럼만 read_key, read_next 증가
- index 조회 + 다른 컬럼도 read key, read_next 증가
- index 스캔 + 인덱스 컬럼만 read_key, read_next 증가
- index 스캔 + 다른 컬럼도 read_key, read_next 증가
파티션 테이블
데이터를 효율적으로 관리하기 위해 데이터를 논리적 또는 물리적으로 분할하는 기능을 제공합니다. 파티션 테이블은 데이터를 파티션 단위로 나누어 관리하므로 검색 성능 향상, 데이터 관리 용이성, 일부 파티션의 데이터 유지 또는 삭제 등의 장점을 제공
대용량 테이블의 성능 향상: 파티션 테이블은 데이터를 여러 파티션에 분산 저장하므로 데이터베이스 검색 작업이 분산되어 처리 속도가 향상 가능.
데이터를 효율적으로 관리하기 위해 데이터를 논리적 또는 물리적으로 분할하는 기능을 제공합니다. 파티션 테이블은 데이터를 파티션 단위로 나누어 관리하므로 검색 성능 향상, 데이터 관리 용이성, 일부 파티션의 데이터 유지 또는 삭제 등의 장점을 제공
대용량 테이블의 성능 향상: 파티션 테이블은 데이터를 여러 파티션에 분산 저장하므로 데이터베이스 검색 작업이 분산되어 처리 속도가 향상 가능.
- 데이터 관리 용이성: 파티션 테이블은 데이터를 논리적 또는 물리적으로 분할하여 관리하기 때문에 데이터 관리 작업이 용이. 특정 파티션에 대한 작업을 수행하거나 파티션 단위로 데이터를 백업하거나 복원 가능.
- 데이터 보관 정책: 파티션 테이블은 데이터의 유효 기간에 따라 파티션을 생성하고 관리. 오래된 데이터를 보관하거나 삭제하는 작업을 효율적으로 수행 가능.
- 파티션 테이블 생성: CREATE TABLE 문을 사용하여 파티션 테이블을 생성. CREATE TABLE 문에서 PARTITION BY 절을 사용하여 파티션 키를 지정하고, 각 파티션의 구성을 정의.
- 파티션 키 선택: 파티션 키는 테이블의 컬럼 중 하나를 선택하여 파티션을 구성하는 데 사용 일반적으로는 날짜, 시간, 범위 등의 기준으로 파티션 키를 선택.
- 파티션 종류 선택: MySQL은 여러 종류의 파티션을 지원. RANGE, LIST, HASH, KEY 등의 파티션 종류 중 하나를 선택하여 파티션 테이블을 생성.
- 프루닝: 파티션 테이블에서 프루닝은 검색 작업 시 불필요한 파티션을 제외하여 검색 범위를 줄이는 작업을 의미. 이를 통해 검색 성능을 향상시킬 수 있다. 쿼리 실행 시 파티션 키를 기반으로 필요한 파티션만을 실제로 접근하여 검색 작업을 수행하도록 하는 것을 의미하는데 쿼리분석, 파티션 키 확인, 프루닝, 쿼리실행의 순서로 동작한다.
- 파티션 삭제: 파티션 테이블에서 특정 파티션을 삭제할 수 있다. DROP PARTITION 문을 사용하여 삭제할 파티션을 지정하고, 해당 파티션의 데이터가 영구적으로 삭제된다.
- 주의할 점 : 파티션키 선택, 파티션 수 제한, 데이터 분산, 파티션 유지관리, 쿼리 최적화, 백업 및 복원
참조
https://hoing.io/archives/4515#DB