PostgreSQL의 테이블 DROP은 트랜잭션 내에서 처리가 가능한 즉 롤백이 가능한 특징을 가지고 있습니다.
이러한 방식은 Lazy 처리 방식으로 인하여 가능합니다.
DDL이 사용되면 처리는 트랜잭션 내에서 여러 메타데이터를 삭제한 뒤 COMMIT이 되면 Pending List에 DROP할 파일을 추가하고 이후 물리 파일을 삭제하는 과정을 거칩니다.
AuroraPostgreSQL은 Aurora의 특징으로 인해 동적으로 물리 파일 크기를 조정합니다.
AuroraPostgreSQL을 운영 및 테스트하던 중 용량이 큰 TABLE을 DROP할 때 CPU가 증가하던 상황을 확인하여 Onpremise의 PostgreSQL과는 다른 구성으로 인한 영향이 어떠한지 확인을 진행해보았습니다.
아래는 각 작업에 대한 정보와 주요 지표들의 변화입니다.
| 작업 트리거 | TABLE A | TABLE B | TABLE C,D,E,F INSERT 입력 부하 추가 |
TABLE G |
| 호출 시간(KST) DROP 처리 시간 |
07:43 약 2초 |
08:15 약 2초 |
09:31 drop TABLEC; Time: 94.222 ms drop TABLED; Time: 1318.130 ms drop TABLCE; Time: 294.751 ms drop TABLED; Time: 536.427 ms |
17:27 1초 미만 |
| 사이즈 | 1820GB | 949GB | TABLEC : 1GB TABLED : 730GB TABLEE : 700MB TABLEF : 374GB |
60GB |
| CPU 증가 | 55% | 55% | 30% 증가 (34% → 65%) | 26% |
| 지표 증가 시간 | 13분 | 9분 | 14분 | 3분 |
| 스토리지 네트워크 사용량 | 385mb/s -> 약 293GB |
370mb/s -> 약 195GB |
340mb/s -> 약 278GB | 약 110MB/S 스파이크로 사용 |
주요 변화 성능 지표
TABLE A, TABLE B DROP 이후 OS 정보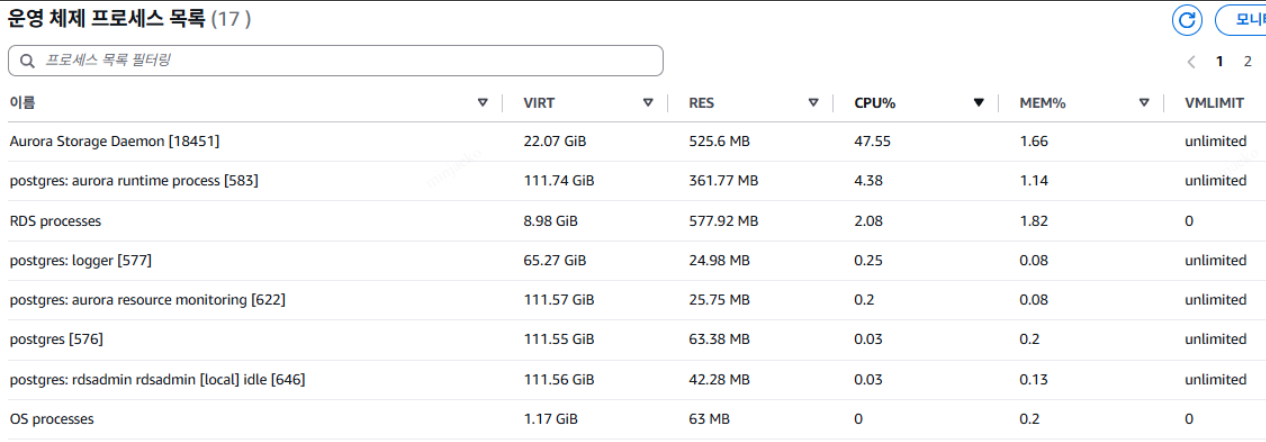 |
INSERT 부하만 진행 중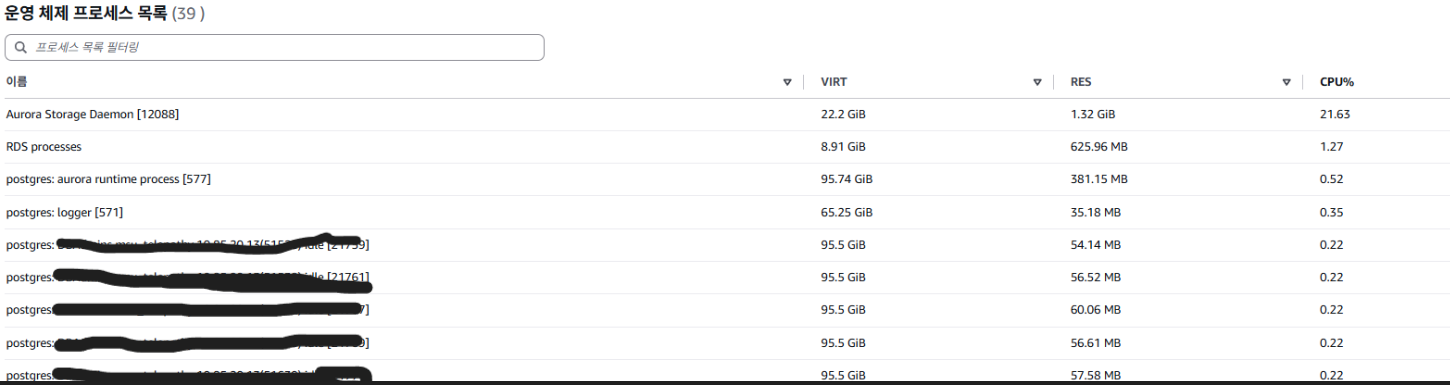 |
INSERT 부하 + TABLE C,D,E,F 삭제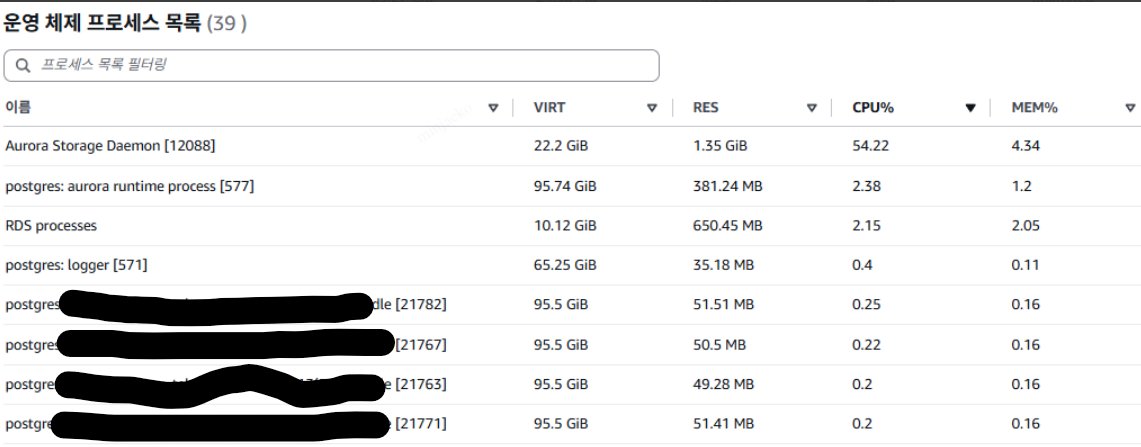 |
각 작업 간 스토리지 네트워크 처리량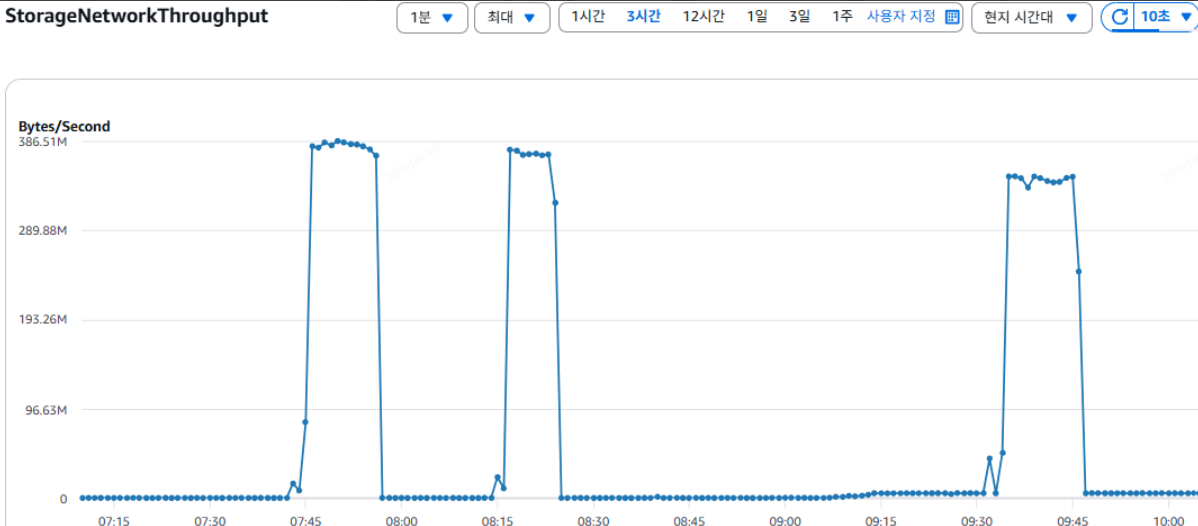 |
각 작업간 WRITE IOPS  |
각 작업간 CPU 사용량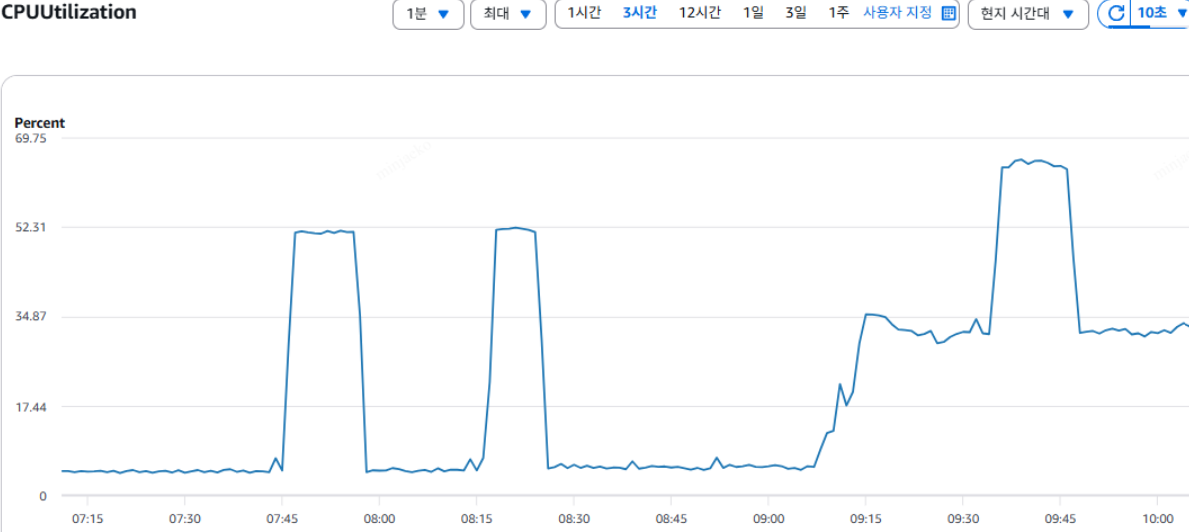 |
입력 부하 변화
progress: 450.0 s, 550.3 tps, lat 36.340 ms stddev 1.186
progress: 460.0 s, 549.6 tps, lat 36.374 ms stddev 1.286
progress: 470.0 s, 547.7 tps, lat 36.549 ms stddev 1.493
progress: 480.0 s, 548.7 tps, lat 36.435 ms stddev 1.421
progress: 490.0 s, 550.0 tps, lat 36.373 ms stddev 1.195
progress: 500.0 s, 549.8 tps, lat 36.371 ms stddev 1.198
progress: 510.0 s, 549.9 tps, lat 36.363 ms stddev 1.228
--TABLE DROP으로 인한 지표 증가 이후
progress: 520.0 s, 462.4 tps, lat 43.218 ms stddev 6.423
progress: 530.0 s, 435.1 tps, lat 45.928 ms stddev 5.665
progress: 540.0 s, 432.0 tps, lat 46.340 ms stddev 6.243
progress: 550.0 s, 433.0 tps, lat 46.146 ms stddev 5.447
progress: 560.0 s, 436.2 tps, lat 45.842 ms stddev 5.534
progress: 570.0 s, 438.1 tps, lat 45.613 ms stddev 5.962
....
progress: 1140.0 s, 438.8 tps, lat 45.634 ms stddev 5.984
progress: 1150.0 s, 441.7 tps, lat 45.239 ms stddev 5.946
progress: 1160.0 s, 440.4 tps, lat 45.400 ms stddev 5.841
progress: 1170.0 s, 438.8 tps, lat 45.525 ms stddev 5.758
progress: 1180.0 s, 441.8 tps, lat 45.352 ms stddev 5.778
progress: 1190.0 s, 446.3 tps, lat 44.791 ms stddev 5.558
progress: 1200.0 s, 444.3 tps, lat 44.968 ms stddev 5.884
progress: 1210.0 s, 449.6 tps, lat 44.584 ms stddev 6.217
progress: 1220.0 s, 444.7 tps, lat 44.933 ms stddev 5.882
--TABLE DROP으로 인한 지표 정상화 이후
progress: 1230.0 s, 527.6 tps, lat 37.906 ms stddev 4.265
progress: 1240.0 s, 549.1 tps, lat 36.395 ms stddev 1.485
progress: 1250.0 s, 548.7 tps, lat 36.467 ms stddev 1.438
progress: 1260.0 s, 545.3 tps, lat 36.674 ms stddev 2.509
progress: 1270.0 s, 549.0 tps, lat 36.418 ms stddev 1.417
지표들을 확이하면 DROP 직후 CPU가 소량 증가한 이후 약간의 시간이 지난뒤 CPU, STORAGE NETWORK, WRITE IOPS 등의 대량 발생을 확인할 수 있습니다. 해당 과정에서 OS 프로세스 리스트는 PostgreSQL 관련 프로세스 사용량이 증가하는 것이 아닌 Aurora Storage Demon이 다수 차지하는 것을 볼 수 있습니다.
즉 PostgreSQL의 메타데이터를 정리하는 작업으로 인하여 CPU가 소량 증가하고 메타데이터 정리라는 공통된 수준의 작업으로 인하여 테이블 사이즈와 크게 상관 없이 시간을 소용한 뒤 Aurora의 특수성으로 인해 여러 DB 인스턴스의 여러 지표가 상승하게 됩니다.
해당 동작은 공통 스토리지를 사용하는 DocumentDB에서도 동일하게 확인이 되었으나 AuroraMySQL에서는 확인되지 않는 작업으로 DBMS 별 차이에 따라 내부 동작 방식이 약간씩 차이가 있는 것으로 확인하였습니다.
StorageNetwork와 CPU는 인스턴스 타입에 따라 제한 사항이 있는 사용량으로 서비스에서 대용량 테이블을 삭제하는 경우 여러 상황을 고려하여 작업 일정을 산출하거나 작업 방식을 수정하는게 필요해보입니다.
'공부 > DATABASE' 카테고리의 다른 글
| Jenkins 로 Terraform 호출하여 AWS RDS 생성하기 (0) | 2026.02.14 |
|---|---|
| [PostgreSQL, MySQL] DBMS에서 인데스 조회 중 I/O 줄이는 방식 (0) | 2026.02.01 |
| [Aurora, PostgreSQL, MySQL] DB 크래쉬 복원 방식 (0) | 2026.01.24 |
| [AWS] Database SavingPlan (0) | 2026.01.24 |
| [Aurora, Aws DocumentDB] I/O Optimized (0) | 2026.01.24 |