
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 게임 개발 파이썬
- SQL SERVER MIGRATION
- 베스트앨범 파이썬
- 프로그래머스 순위
- SQL SERVER 장비교체
- SWEA
- 백준 11054.가장 긴 바이토닉 부분 수열
- 프로그래머스 순위 파이썬
- 등굣길 파이썬
- 순위 파이썬
- 반도체 설계 파이썬
- 프로그래머스 가장 긴 팰린드롬
- 가장 긴 바이토닉 부분 수열 파이썬
- 프로그래머스 등굣길
- 백준 1613 역사
- 가장 긴 팰린드롬 파이썬
- 백준 1516 게임 개발
- 백준 2352 반도체 설계 파이썬
- 백준 1043 거짓말 파이썬
- 트리의 지름 파이썬
- 램프 파이썬
- 역사 파이썬
- 백준 1238 파티 파이썬
- 프로그래머스 베스트앨범
- 프로그래머스 여행경로
- 백준 1167 트리의 지름 파이썬
- 다중 컬럼 NOT IN
- 백준 2146 다리 만들기
- 백준 1034 램프 파이썬
- 다리 만들기 파이썬
- Today
- Total
공부, 기록
[AWS] OpenSearch Service 본문
Amazon OpenSearch Service (이하 OSS)는 AWS 클라우드에서 OpenSearch 클러스터를 쉽게 배포, 운영 및 확장할 수 있는 관리형 서비스입니다.
OpenSearch : 로그 분석, 실시간 애플리케이션 모니터링, 클릭스트림 분석과 같은 사용 사례를 위한 완전한 오픈 소스 검색 및 분석 엔진입니다.
AWS OSS는 OpenSearch 클러스터의 모든 리소스를 프로비저닝하고 실행합니다. 또한 장애가 발생한 OpenSearch 서비스 노드를 자동으로 탐지하고 교체하여 자체 관리형 인프라와 관련된 오버헤드를 줄입니다. API를 한 번만 호출하거나 콘솔에서 몇 번만 클릭하여 클러스터를 조정할 수 있습니다.

https://docs.aws.amazon.com/ko_kr/opensearch-service/latest/developerguide/what-is.html
OSS 의 특징
크기 조정
- 비용 효율적인 Graviton 인스턴스를 포함한 다양한 CPU, 메모리 및 스토리지 인스턴스 구성
- 최대 3PB의 스토리지
- 읽기 전용 데이터를 위한 비용 효율적인 UltraWarm, Cold Storage 제공
보안
- IAM을 통한 액세스 제어
- Amazon VPC 및 VPC 보안 그룹을 사용
- 저장 데이터 암호화 및 node-to-node 암호화
- OpenSearch 대시보드를 위한 Amazon Cognito, HTTP 기본 또는 SAML 인증
- 인덱스, 문서, 필드 수준의 보안
- 감사 로그 제공
- Dashboards 멀티테넌시 제공
안정성
- 리소스를 위한 여러 리전과 AZ.
- 동일 리전간 MultiAZ 제공
- 클러스터 관리 작업 부담을 줄여주는 전용 프라이머리 노드
- 서비스 도메인을 백업하고 복원하는 자동 스냅샷
유연성
- 비즈니스 인텔리전스(BI) 애플리케이션과의 통합을 위한 SQL 지원
- 검색 결과 향상을 위한 커스텀 가능
유명 서비스와의 통합
- 대시보드를 사용한 OpenSearch 데이터 시각화
- CloudWatch Amazon과의 통합으로 OpenSearch 서비스 도메인 메트릭을 모니터링하고 경보를 설정할 수 있습니다.
- OpenSearch 서비스 도메인에 대한 AWS CloudTrail API 호출을 감사하기 위한 구성 통합 제공
- Amazon S3, Amazon Kinesis 및 Amazon DynamoDB 스트리밍 데이터를 OpenSearch 서비스로 로드
- 데이터가 특정 임계값을 초과하는 경우 Amazon SNS의 알림
비용
- OpenSearch 서비스의 경우 EC2 인스턴스 사용 시간당 및 인스턴스에 연결된 EBS 스토리지 볼륨의 누적 크기에 대해 요금을 지불합니다
- 표준 AWS 데이터 전송 요금도 적용
OSS 관련 용어
Index : 테이블과 유사한 개념으로 문서가 저장되는 오브젝트
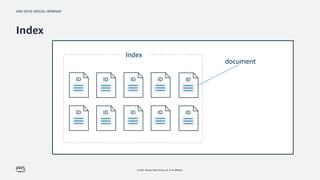
document : 데이터 단위 (row와 비슷한 개념)
field : 컬럼과 비슷한 개념

쿼리는 curl 또는 opensearch 라이브러리를 사용한다.
또는 추가 플러그인을 사용하여 sql 구문 사용이 가능하다.
https://docs.aws.amazon.com/ko_kr/opensearch-service/latest/developerguide/sql-support.html
https://opensearch.org/docs/latest/search-plugins/sql/sql/index/
OpenSearch가 검색, 분석, 로그 처리 등의 용도로 쓰이는 이유가 뭘까? Lucene 엔진의 힘으로 빠른 처리가 가능
구조
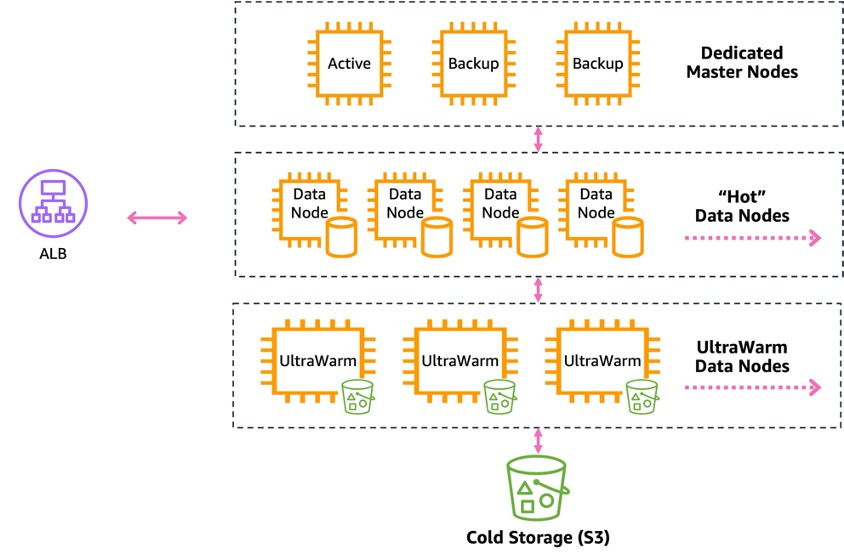
도메인 : OpenSearch 클러스터
마스터노드 : 클러스터의 전체 노드, 인덱스, 샤드에 대한 추적과 라우팅, 상태 업데이트 등 리소스 관리 작업을 전담
데이터 노드 : 실제로 인덱싱된 데이터를 저장하고 있는 노드로 검색과 쿼리 요청을 수행
- Hot: 데이터에 대한 빠른 액세스를 제공하며 인덱싱 및 업데이트에 사용됩니다. 각 노드에 연결된 인스턴스 저장소나 Amazon EBS 볼륨이 사용됩니다.
실시간 분석 및 자주 액세스가 필요한 데이터를 저장할 때 적합하며, 가장 높은 성능을 제공하는 대신 비용도 가장 높습니다. - UltraWarm: Amazon S3 를 사용하여 읽기 전용 데이터를 저장하는데, 성능 향상을 위해 캐싱 솔루션이 함께 사용됩니다.
자주 쿼리하지 않는 읽기 전용 데이터에 대해서 Hot 스토리지 만큼의 성능은 필요 없는 경우 비용 효과적으로 활용할 수 있습니다.
데이터를 수정을 위해서는 Hot 스토리지로 이동한 뒤 수정을 해야합니다. 데이터에 처음 접근할 때 S3 에서 데이터를 UltraWarm 노드로 이동시켜 캐싱하기 때문에 후속 쿼리에 대해서는 성능이 올라갑니다. - Cold 스토리지: 액세스 빈도가 매우 낮은 데이터를 오랫동안 보관하는 것에 최적화 되어 있습니다.
인스턴스가 없기 때문에 Cold 스토리지의 데이터는 직접 검색할 수 없으며, UltraWarm 계층으로 데이터를 가져온 뒤에 접근할 수 있습니다.
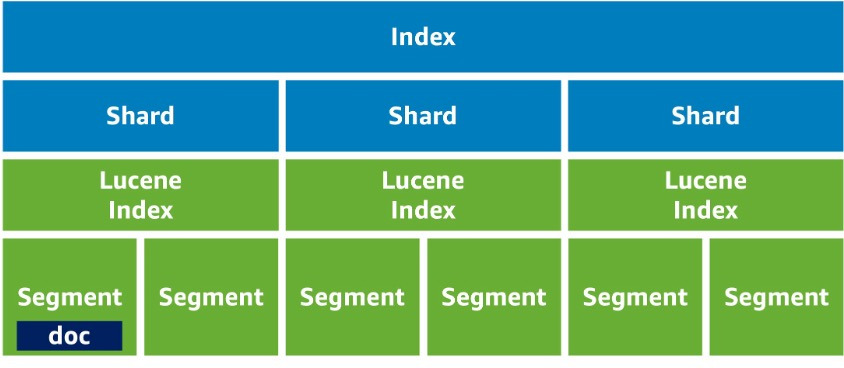
Index : 단일 데이터 단위인 document가 모인 전체 데이터 세트
SHARD : 데이터를 분산 저장하기 위해 Index의 범위를 나눈 것.
Lucene Index : 내부적으로 Lucene 을 사용하기 때문에 샤드는 Lucene Index와 1:1로 연결 됩니다.
Lucene는 오픈소스 정보 검색 라이브러리로, 텍스트 검색, 색인화, 및 문서 처리를 지원하는 강력한 엔진으로 OpenSearch에서는 내부적으로 Lucene 엔진을 사용하여 데이터 검색 및 분석을 처리합니다.
주요 기능
- 텍스트 검색: Lucene은 주로 텍스트 기반의 데이터를 색인하고 검색하는 데 사용됩니다. 이를 통해 대규모 데이터에서도 매우 빠르고 효율적으로 텍스트를 검색할 수 있습니다.
- 색인화(Indexing): Lucene은 텍스트 데이터를 작은 단위로 분할하고, 이러한 분할된 데이터(토큰)를 색인에 저장합니다. 이를 통해 문서 검색 시 매우 빠른 응답 속도를 보장합니다.
- 검색 쿼리(Query): Lucene은 매우 정교한 쿼리 언어를 제공하여 사용자가 특정 문서나 정보를 검색할 수 있도록 도와줍니다. 쿼리 작성 시 다양한 필터링 및 매칭 옵션을 사용할 수 있습니다.
Segment : Lucene Index 인덱스가 문서를 나누는 단위
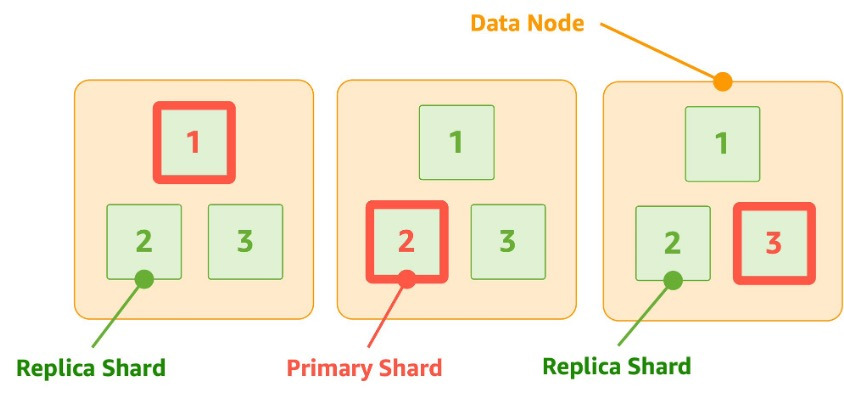
샤드는 Primary와 Replica 로 나뉘어지고 이 하나의 묶음을 데이터 노드라고 합니다.
- Primary Shard : 오리지날(Original) 샤드라고도 하며, 인덱스 내의 데이터를 보관하고 실제 검색 및 쿼리가 이루어 집니다.
- Replica Shard: 각 기본 샤드의 복제본으로 내구성 및 처리량 향상에 사용됩니다. 기본 샤드와는 다른 데이터 노드에 분산됩니다.
https://aws.amazon.com/ko/blogs/tech/opensearch-sizing/
https://www.slideshare.net/awskorea/t2s2pdf#10
'공부 > DATABASE' 카테고리의 다른 글
| Valkey의 멀티스레드 아키텍처 (0) | 2024.10.12 |
|---|---|
| [AWS] DynamoDB (0) | 2024.09.15 |
| [PostgreSQL] Aurora PostgreSQL의 Shared Buffer 기본값 (0) | 2024.09.15 |
| [AWS] Aurora 공부 3 (모니터링) (0) | 2024.09.15 |
| [REDIS] Redis의 복제와 클러스터 (0) | 2024.09.15 |



