
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 백준 1034 램프 파이썬
- 백준 1238 파티 파이썬
- 게임 개발 파이썬
- 다리 만들기 파이썬
- 역사 파이썬
- 프로그래머스 베스트앨범
- 백준 1613 역사
- 순위 파이썬
- 가장 긴 팰린드롬 파이썬
- 백준 2352 반도체 설계 파이썬
- 백준 11054.가장 긴 바이토닉 부분 수열
- 트리의 지름 파이썬
- 프로그래머스 순위 파이썬
- 가장 긴 바이토닉 부분 수열 파이썬
- 백준 1516 게임 개발
- 백준 1167 트리의 지름 파이썬
- 반도체 설계 파이썬
- 백준 1043 거짓말 파이썬
- 프로그래머스 순위
- 프로그래머스 가장 긴 팰린드롬
- SQL SERVER MIGRATION
- 다중 컬럼 NOT IN
- SWEA
- 램프 파이썬
- 베스트앨범 파이썬
- 프로그래머스 여행경로
- SQL SERVER 장비교체
- 프로그래머스 등굣길
- 백준 2146 다리 만들기
- 등굣길 파이썬
- Today
- Total
공부, 기록
[SQL Server] Index Seek 에서 클러스터드 인덱스 조건이 주는 영향도 본문
Nonclustered index로 조회할 때 인덱스에 해당하는 컬럼에 의해서만 인덱스 페이지에 접근을 하고 그 이후 Clustered Key 를 통하여 lookup이 발생한다고 생각하였다.
결과적으로 where 구문에 Nonclustered index의 컬럼과 Clustered Index의 컬럼이 모두 존재할 때 인덱스가 Nonclustered가 채택이 된다면 실제 조회는 두개의 조건을 모두 사용하여 인덱스 페이지에 접근을 하고 이는 Nonclustered index의 컬럼만 있는 경우보다 케이스에 따라 더 좋은 성능을 만들어준다.
예.
테스트
create table minjae_test2 (col1 int identity(1,1), col2 int, col3 datetime)
create clustered index test_1 on minjae_test2 (col3)
create index test_2 on minjae_test2 (col2)
alter table minjae_test2 add constraint pk_minjae primary key (col1)
1. Nonclustered Index 컬럼만 존재할 때
select * from minjae_test2 with (nolock, index = test_2) where col2 = 200

Table 'minjae_test2'. Scan count 1, logical reads 10339, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
2. Nonclustered Index 컬럼과 별도 조건이 존재할 때
(별도 인덱스는 seek에 영향을 주지 못함)
select * from minjae_test2 with (nolock, index = test_2) where col2 = 200 and col1 < 8000

Table 'minjae_test2'. Scan count 1, logical reads 10339, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
3. Nonclustered Index 컬럼만 Clustered Index 조건이 함께 존재할 때
(clustered index의 조건으로 인하여 index seek 범위가 줄어든다)
select * from minjae_test2 with (nolock, index = test_2) where col2 = 200 and col1 < 8000 and col3 between '2024-05-22' and '2024-05-23'
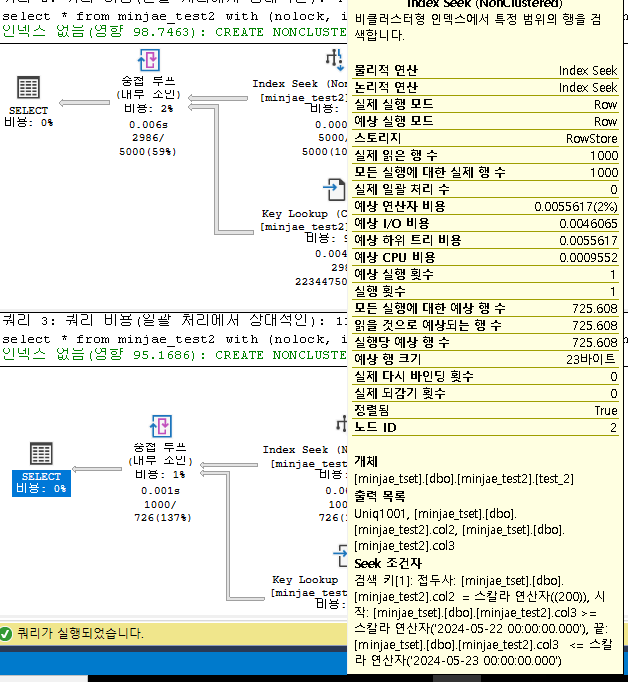
Table 'minjae_test2'. Scan count 1, logical reads 2077, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Index Seek에 대하여는 Index 컬럼의 분포도만 사용된다고 생각하였던 부분이 잘못된 것을 알게되었고
Clustered Index 컬럼 설정의 중요성에 대하여 더 신중해야할 것 같다는 생각이 들었다.
'공부 > DATABASE' 카테고리의 다른 글
| [AWS RDS SQL Server] 인증서 변경 (0) | 2024.05.31 |
|---|---|
| [AWS RDS SQL Server] 데이터 업데이트 작업 (0) | 2024.05.30 |
| [SQL Server] Insert와 버퍼캐시 (0) | 2024.05.27 |
| [RDS SQL Server] 인스턴스 타입 변경 (0) | 2024.05.21 |
| [SQL SERVER ] HA 헬스 체크 방식 (0) | 2024.05.14 |


