
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- SQL SERVER MIGRATION
- 프로그래머스 여행경로
- 백준 1516 게임 개발
- 베스트앨범 파이썬
- 다중 컬럼 NOT IN
- 백준 1043 거짓말 파이썬
- SQL SERVER 장비교체
- 백준 1613 역사
- 가장 긴 바이토닉 부분 수열 파이썬
- SWEA
- 등굣길 파이썬
- 프로그래머스 순위
- 백준 11054.가장 긴 바이토닉 부분 수열
- 백준 1167 트리의 지름 파이썬
- 트리의 지름 파이썬
- 프로그래머스 베스트앨범
- 백준 2146 다리 만들기
- 순위 파이썬
- 램프 파이썬
- 가장 긴 팰린드롬 파이썬
- 프로그래머스 순위 파이썬
- 역사 파이썬
- 다리 만들기 파이썬
- 백준 1238 파티 파이썬
- 반도체 설계 파이썬
- 백준 1034 램프 파이썬
- 백준 2352 반도체 설계 파이썬
- 프로그래머스 가장 긴 팰린드롬
- 게임 개발 파이썬
- 프로그래머스 등굣길
- Today
- Total
공부, 기록
[R&D]MongoDB 본문
3.0
컬렉션 수준 잠금에 대한 지원을 추가.
복제 세트 멤버 수 증가.
SCRAM-SHA-1 인증 추가.
WiredTiger 스토리지 엔진 지원.
3.2
WiredTiger 스토리지 엔진을 기본 값으로 사용
복제 선택 향상(복제본 세트 장애 조치 시간을 줄이고 여러 동시 기본 항목의 감지를 가속화)
샤딩 클러스터 향상(분할된 클러스터의 구성 서버를 복제 본 세트로 배포 가능)
Partitial 인덱스 지원.(필터 인덱스)
집계 프레임 워크 향상
텍스트 검색 향상
3.4
샤딩 클러스터 향상(이름, 구성 서버의 위치 클러스터의 멤버 인식)
group 대신 aggregate 또는 mapReduce 메소드 사용.
aggregation 향상 (단계 및 연산자 추가)
mongoreplay 지원
3.6
보안 기능 향상
aggregation 향상 ($lookup 향상, 집계 단계 및 연산자 추가)
4.0
다중 문서 트랜잭션 기능 제공
aggregation 향상 (연산자 추가, bucket 단계가 더 이상 필요하지 않음)
보안 기능 향상 (SCRAM-SHA-256 지원)
MMAPv1 지원 중단
마스터-슬레이브 복제 지원 중단
4.2
분산 트랜잭션 도입.
MMAPv1 엔진 제거.
aggregation 개선 ($merge 단계 추가, 삼각함수 추가, $round 표현식 추가)
update 향상
와일드 카드 인덱스 지원(.$**)
community에서 Storage Node Watchdong 사용 가능
인덱스 이름 길이 제한, 인덱스 키 크기 제한 제거
query plan 개선
4.4
aggregation 개선(연산자 추가)
복제 개선 (스트리밍 복제)
미러링된 읽기 제공(가장 최근에 액세스 한 데이터를 사용하여 구성원 캐시에 제공)
샤딩 클러스터 개선
$meta 키워드 지원(find와 함께 사용)
다중 LDAP 비밀번호 지원
hide 인덱스 지원

WiredTiger 스토리지 엔진
dbpath : 데이터 파일이 저장되는 경로.
journal : 서버의 저널로그(=트랜잭션 로그) 활성화 여부 결정.
WiredTiger 엔진은 3가지 타입의 저장소를 가지고 있음.
레코드 스토어 : 일반적인 RMDS가 저장하는 방식. B-Tree 알고리즘 사용(몽고에서 사용하는 방식).
컬럼 스토어 : 대용량 분석 용도로 사용. 데이터 파일의 크기가 작고 속도가 빨라 대용량 분석에 적합.
LSM(Log Structured Merge Tree) 스토어 : NoSQL에서 가장 자주 사용하는 저장방식. write에 집중한 방식으로 b-tree가 아닌 순차 파일 형태로 데이터 저장.
B-TREE 구조의 데이터 파일과 데이터 복구를 위한 저널로그를 가지고 있음. 새로운 로그 파일을 생성하고 지난 사용하지 않는 파일은 자동으로 삭제하는 방식.
공유캐시 : WiredTiger 엔진은 내부에서 캐시를 사용. 디스크의 데이터 페이지가 캐시로 공유될 때 메모리에 적합한 트리 형태로 재구성되어 별도의 맵핑 없이 메모리 주소를 이용해 바로 검색 가눙.
Hazrad Pointer : WiredTiger에서 필요 없어진 캐시를 삭제하는 방식
Skip-List : RDMS의 Undo와 비슷한 역할. 다만 데이터 페이지의 레코드를 직접 변경하지 않고 변경된 데이터를 skip-list에 추가. 사용자는 쿼리가 데이터를 읽을 때 변경 이력이 저장된 skip-list를 검색해서 원하는 시점의 데이터를 읽음 → 쓰기 작업의 처리 속도를 높여서 동시 처리 성능을 향상
Checkpoint : 3.6 버전부터 60초 간격으로 체크포인트 생성.
데이터 블록(페이지) : WiredTiger는 고정된 크기의 페이지를 사용하지 않지만 최대 크기에 대해서는 제한이 있음.
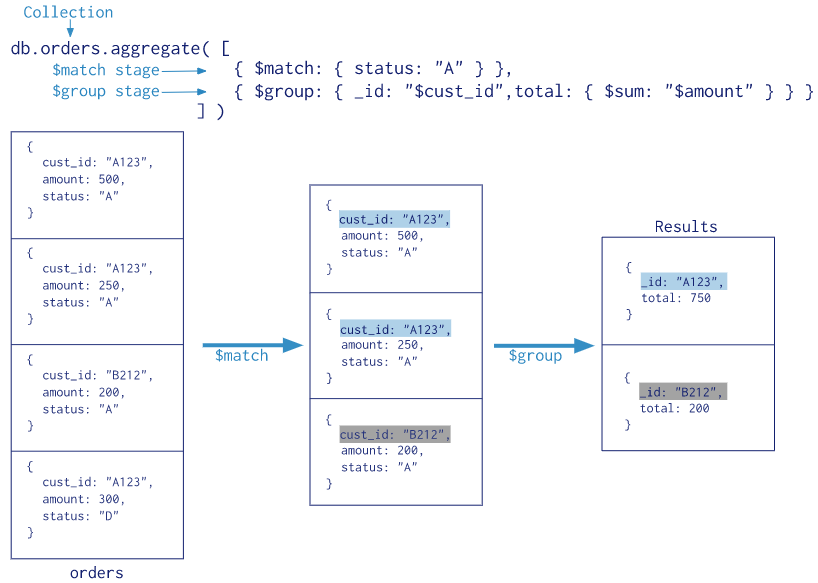
Aggregation
pipeline과 Map-Reduce 방식이 있는데 주로 pipeline 방식으로 사용된다.
pipeline : 이전 단계의 연산 결과를 다음 단계에 이용하는 것
MongoDB Sharding 구조
샤딩은 여러 시스템에 데이터를 배포하는 방법. 샤딩에는 수직 및 수평 확장 두 가지가 존재. 몽고db는 수평 확장 지원
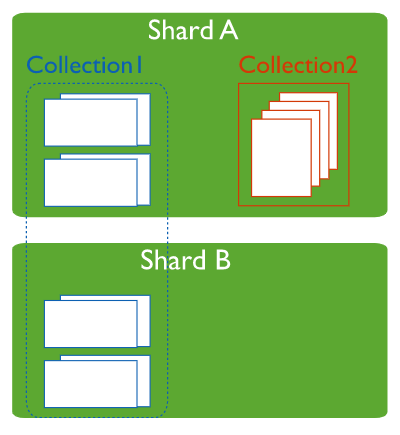
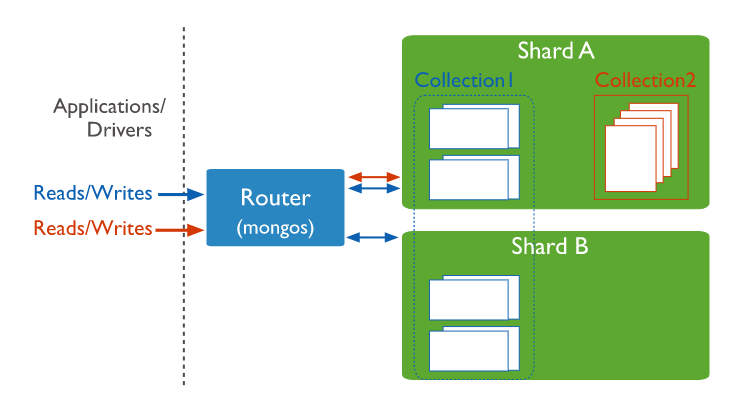
Shard: 각 샤드는 분할 된 데이터의 하위 집합을 포함. 각 샤드는 복제본 세트로 배포 가능 .
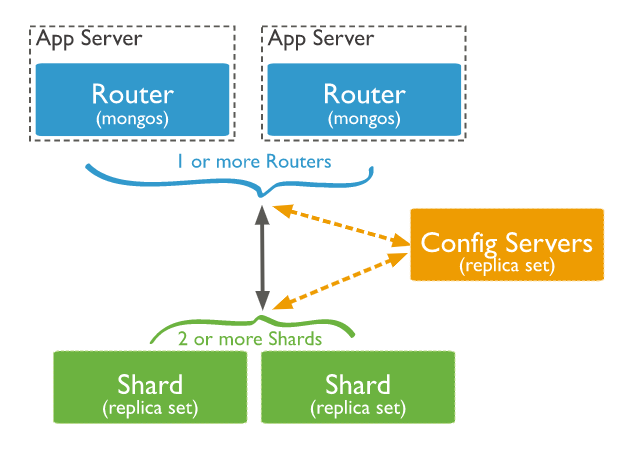
mongos : 클라이언트 애플리케이션과 분할 된 클러스터 간의 인터페이스를 제공하는 쿼리 라우터 역할. MongoDB 4.4부터 지연 시간을 최소화하기 위해 헤지 읽기를 지원 .
Config Servers(mongod) : 구성 서버는 클러스터에 대한 메타 데이터 및 구성 설정을 저장.
shard key를 사용하여 shard 에 collection, document를 배포
Sharding의 장점 : read/write에 대해 성능 확보. 고 가용성 확보
HASH Sharding : 해시키 값을 바탕으로 데이터를 분포.
Range Sharding : 분할 키 값에 따라 데이터를 범위로 나누어서 분포.
복제
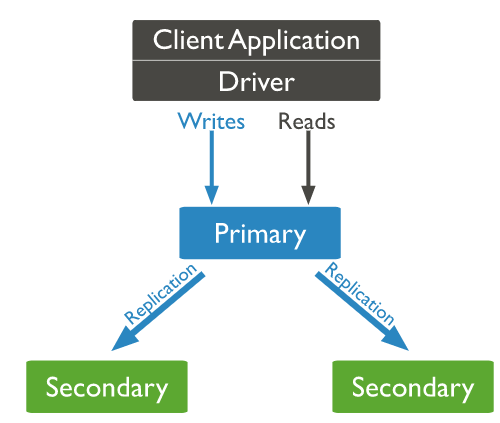
OpLog(Operation Log) : MongoDB의 복제를 위해서 만 사용. 컬렉션의 레코드 형태로 저장.
MongoDB는 Secondary(구독)가 Primary(게시)에서 OpLog를 가져와 재생하여 데이터를 동기화 함.
OpLog 구조
Local 데이터베이스에 oplog.rs 컬렉션에 기록
ts(Timestamp) : 동기화를 잠시 중단하거나 재시작할 때 기준.
t(Primary Term) : 복제 셋의 Primary 선출하는 투표가 실행 시 증가.
h(Hash): OpLog의 도큐먼트는 Primary 멤버에서 실행된 데이터 변경작업을 의미, 각각의 작업에는 OpLog의 해시 값을 이용해서 식별자가 할당되는데 이 식별자를 h 필드에 저장.
v(Version): 도큐먼트의 버전을 의미.
op(Operation Type): i(Insert),d(Delete),u(Update),c(Command),n(No Operation) 등 오퍼레이션 종류를 저장. n은 단순 정보 저장.
ns(Namespace): 데이터가 변경된 컬렉션의 네임스페이스가 저장.
o(Operation): op필드에 저장된 오퍼레이션 타입별로 실제 변경된 정보가 저장
o2(Operation 2): op필드가 u인 경우에만 o2 필드가 존재. 업데이트 될 대상 도큐먼트의 _id 정보를 저장.
MongoDB는 Primary가 죽었을 때 Secondary에서 자동으로 하나가 Primary로 선출됨 이 과정을 투표라 함.
복제지연 : 복제하는데 걸리는 시간. 4.2 버전부터 지연 시간 제한 가능
아비터서버 : 감시용 서버로 문제가 생긴 서버를 대신해서 primary 동작할 서버를 지정하는 서버
PSS
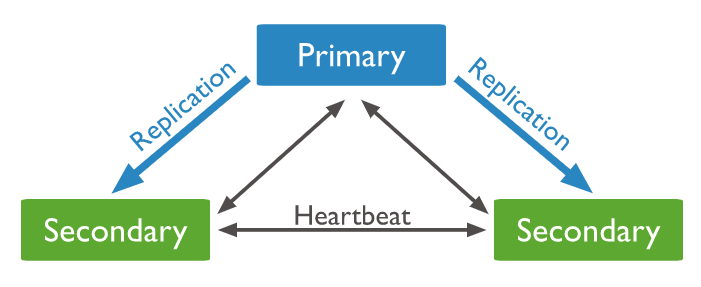
하나의 Primary와 여러 개의 Secondary로 이루어진 Replica Set
Primary가 죽을 경우 투표를 통해 남은 Secondary 중 새로운 Primary를 선출한다.
만약 Secondary가 하나만 남았다면 새로운 Primary를 선출할 수 없어 서버 장애가 발생
PSA
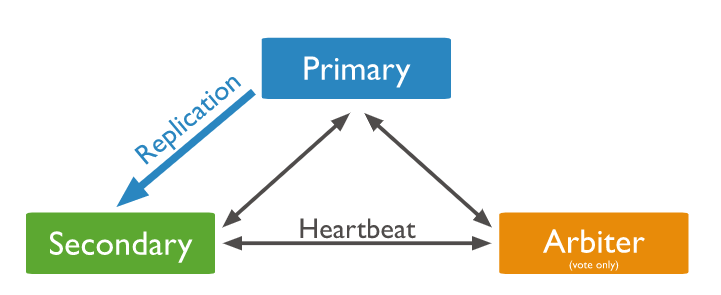
하나의 Primary와 Arbiter 그리고 여러 개의 Secondary로 이루어진 Replica Set
Primary가 죽은 경우 Arbiter가 Secondary와 함께 투표해서 Secondary 중 새로운 Primary를 선출한다.
P-S-A 시스템에선 Secondary가 하나만 남았더라도 Arbiter가 남아있어서 남은 Secondary를 Primary로 선출 할 수 있어서 정상적으로 서비스가 동작
트랜잭션
4.0 버전부터 multi-document transaction 지원(복제 set 내에서만 4.2 부터는 샤딩에도 포함)
RDBMS와 다르게 LOCK이 걸리면 대기하지 않고 에러 발생 처리함.
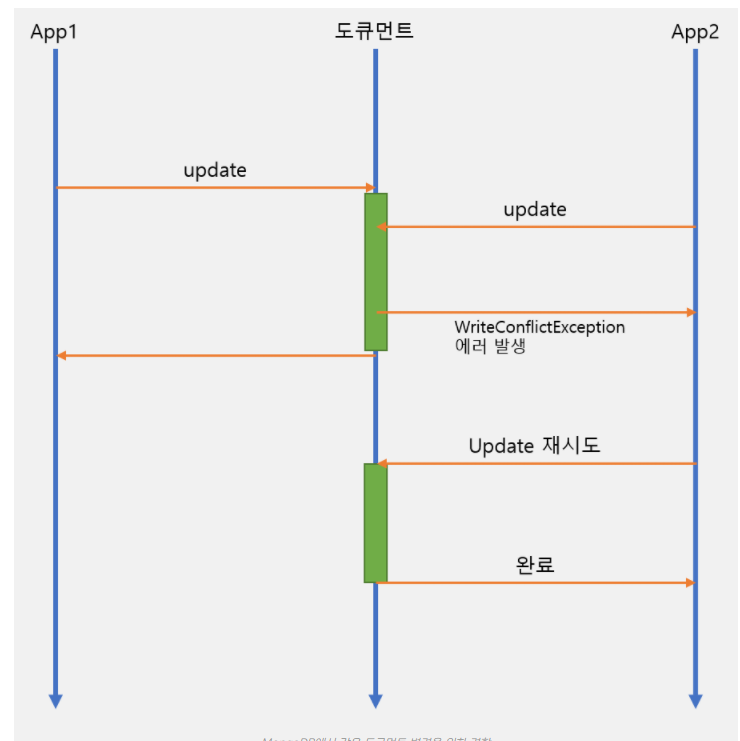
격리수준
snapshot isolation(=repetable-read,default)
Read Concern (= read isolation) : Replica 간 동기화 과정 중에 데이터 읽기를 일관성 있게 유지할 수 있도록 옵션으로 제공됨. 옵션으로는 local, majority, linearizable이 있음
local : Default 값으로 가장 최신의 데이터를 반환하는 방식. 주로 Primary에서 가져감 장애 발생 시 해당 데이터가 롤백되어 phantom read가 발생 가능.
majority : 다수의 멤버들이 최신 데이터를 가지고 있는 경우 반환.
linearizable : 모든 멤버가 가진 사항에 관해서 만 반환.
쿼리계획
mongod 를 재시작 또는 종료하면 쿼리 계획 캐시가 삭제됨.
인덱스, 컬렉션 수정 작업을 하면 쿼리 계획 캐시 삭제.
LRU 캐시 교체 메커니즘에 의해 가장 오랫동안 참조되지 않은 캐시 항목을 삭제함.
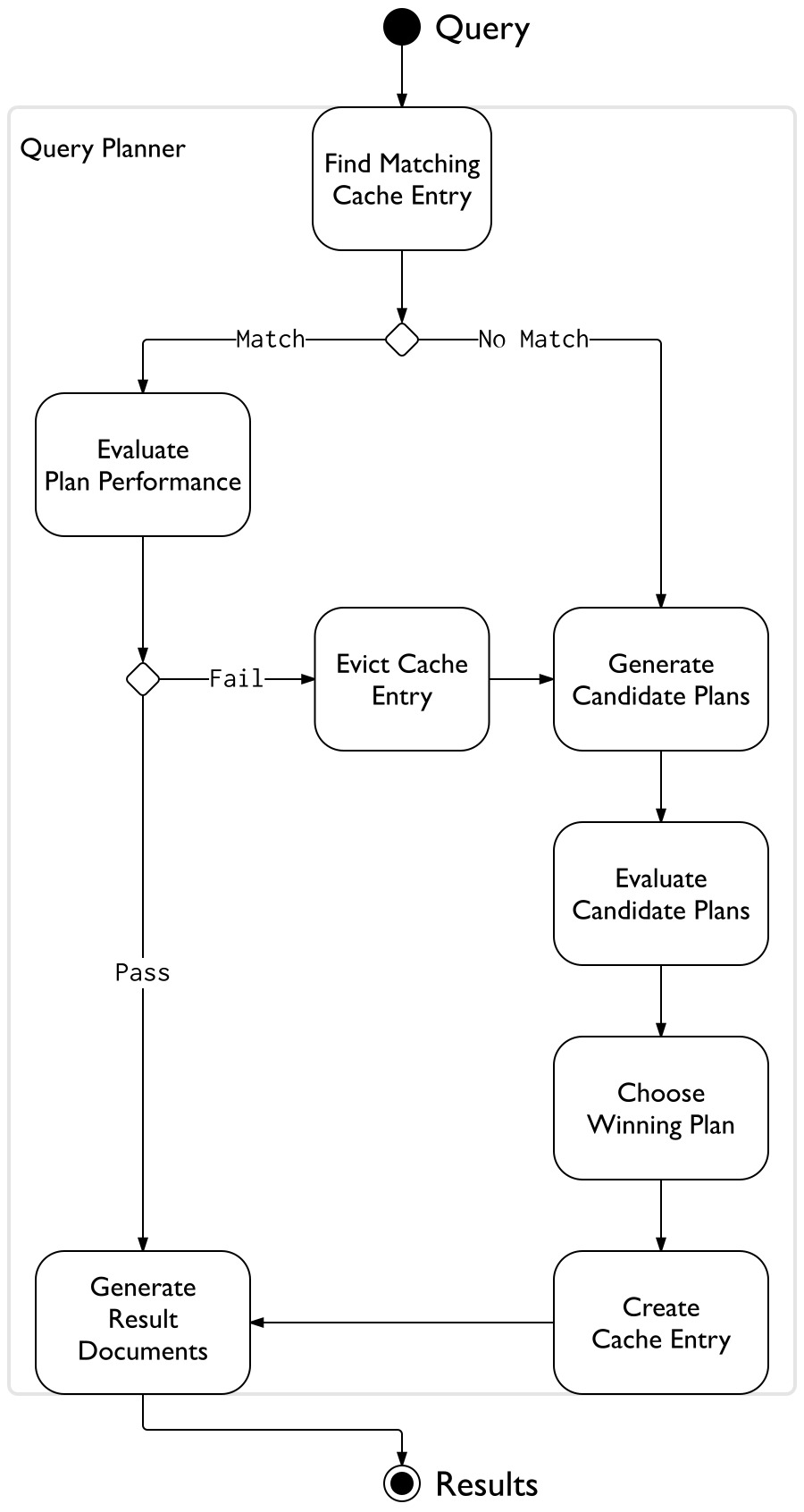
인덱스
기본 인덱스 (_id) : 컬렉션에 존재하는 _id 필드에 인덱스가 존재.
단일 필드 인덱스 : 사용자가 단일 필드를 지정하는 인덱스.
복합 인덱스 : 두개 이상의 필드를 사용하는 인덱스.
다중 키 인덱스 : 필드 타입이 배열인 필드에 인덱스를 적용할 경우.
텍스트 인덱스 : 텍스트 관련 데이터를 효율적으로 처리하기 위한 인덱스.
공간적 인덱스 : 지도의 좌표와 같은 데이터를 처리하기 효율적인 인덱스.
hash 인덱스 : B-Tree가 아닌 Hash 자료구조를 사용하는 인덱스.
4.4 버전부터 인덱스 숨기기 기능 지원.
인덱스 확인 : db.collection.getIndexes()
인덱스 제거 : db.collection.dropIndex()
MongoDB Storage 엔진 비교 (최근 버전은 WiredTiger, In-Memory만 지원)
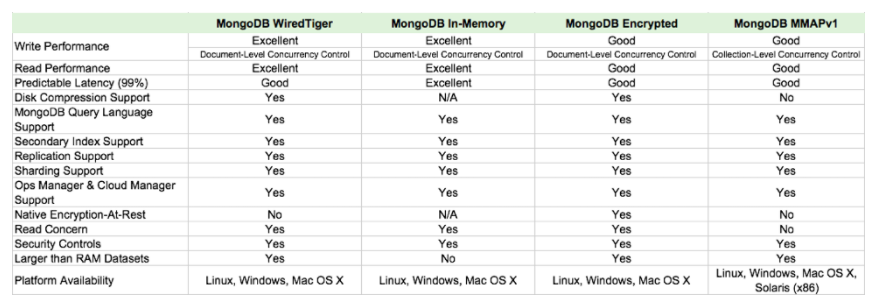
'공부 > DATABASE' 카테고리의 다른 글
| [MSSQL/SQL Server] 트랜잭션 (0) | 2022.09.24 |
|---|---|
| 캐시와 실행계획 (0) | 2022.05.21 |
| [R&D]MySql (0) | 2022.03.16 |
| [R&D]SQL Server (0) | 2022.03.16 |
| 트레이스, 프로파일러 (0) | 2022.03.16 |


